|
|
Статическая и динамическая типизацияЕсли типпеременной определяется на этапе компиляции, имеет место статическая типизация, а если на этапе выполнения программы — динамическая. В последнем случае иногда говорят, что переменная не имеет типа, хотя данные, содержащиеся в ней, безусловно, относятся к определённому типу данных, но выясняется это уже во время выполнения программы. В большинстве случаев статическая типизация позволяет уменьшить затраты ресурсов при выполнении программы, поскольку для динамической типизации требуются затраты ресурсов на выяснение типов данных, их приведение в выражениях с смешанными типами. Статическая типизация позволяет перекладывать проверку типов на этапе компиляции программы. Это также упрощает обнаружение ошибок ещё на этапе разработки, когда их исправление обходится менее дорого. Тем не менее, во многих случаях необходимо применение динамической типизации. Например, необходимость поддержания совместимости при переходе на новый формат представления данных (например, старая часть проекта посылает процедуре дату символьной строкой, а новые объекты используют более современный числовой тип). Статические и динамические переменные Адрес поименованной ячейки памяти также может определяться как на этапе компиляции, так и во время выполнения программы. По времени создания переменные бывают статическими и динамическими. Первые, создаются в момент запуска программы или подпрограммы, а вторые создаются в процессе выполнения программы. Динамическая адресация нужна только тогда, когда программист заранее не может точно знать количество поступающих на обработку данных. Такие данные размещают в специальных динамических структурах, тип которой программист выбирает сообразно специфике задачи, а также возможностям своей системы программирования. Это может быть стек, куча, очередь и т.п. Даже файл, в том смысле, который заложил Н.Вирт в Паскаль, является динамической структурой. Локальные и глобальные переменные. Зоны видимости По зоне видимости различают локальные и глобальные переменные. Первые доступны только конкретной подпрограмме, вторые — всей программе. С распространением модульного и объектного программирования, появились ещё и общие переменные (доступные для определённых уровней иерархии подпрограмм). Ограничение зоны видимости придумали как для возможности использовать одинаковые имена переменных (что разумно, когда в разных подпрограммах переменные выполняют похожую функцию), так и для защиты от ошибок, связанных с неправомерным использованием переменных (правда, для этого программист должен владеть и пользоваться соответствующей логикой при структуризации данных). Простые и сложные переменные По наличию внутренней структуры, переменные могут быть простыми или сложными (составными). Простые переменные не имеют внутренней структуры, доступной для адресации. Последняя оговорка важна потому, что для компилятора или процессора переменная может быть сколь угодно сложной, но конкретная система (язык) программирования скрывает от программиста её внутреннюю структуру, позволяя адресоваться только "в целом". Сложные переменные программист создаёт для хранения данных, имеющих внутреннюю структуру. Соответственно, есть возможность обратиться напрямую к любому элементу. Самыми характерными примерами сложных типов являются массив (все элементы однотипные) и запись (элементы могут иметь разный тип). Следует подчеркнуть относительность такого деления: для разных программ одна и та же переменная может иметь разную структуру. Например, компилятор различает в переменной вещественного типа 4 поля: знаки мантиссы и порядка, плюс их значения, но для программиста, компилирующего свою программу, вещественная переменная — единая ячейка памяти, хранящая вещественное число. Соглашения об именовании переменных. Венгерская нотация Венге́рская нота́ция (в программировании) — соглашение об именовании переменных, констант и прочих идентификаторов в коде программ. Своё название венгерская нотация получила благодаря программисту компании Майкрософт венгерского происхождения Чарльзу Симони (венг. Simonyi Károly), предложившего её ещё во времена разработки первых версий MS-DOS. Эта система стала внутренним стандартом Майкрософт. Суть венгерской нотации сводится к тому, что имена идентификаторов предваряются заранее оговорёнными префиксами, состоящими из одного или нескольких символов. При этом, как правило, ни само наличие префиксов, ни их написание не являются требованием языков программирования, и у каждого программиста (или коллектива программистов) они могут быть своими. Применяемая система префиксов зависит от многих факторов: 1. языка программирования; 2. стиля программирования (объектно-ориентированный код может вообще не требовать префиксов, в то время как в «монолитном» для разборчивости они зачастую нужны); 3. предметной области (например, префиксы могут применяться для записи единиц измерения); 4. доступных средств автоматизации (генератор документации, навигация по коду, предиктивный ввод текста и т.д.). // Примеры
Как видно в приведённом примере, префикс может быть и составным. Например, для именования строковой переменной-члена класса использована комбинация префиксов «m_» и «s» (m_sAddress). Среди программистов есть как сторонники, так и противники использования венгерской нотации. Противники утверждают, что она громоздка и лишь ухудшает понимание кода. Сторонники утверждают, что слишком многие неверно понимают основную идею и неправильно пользуются нотацией. Далее приводятся основные доводы сторон. Достоинства
Недостатки
Известный противник венгерской нотации — Линус Торвальдс: «Вписывание типа переменной в её имя (так называемая венгерская нотация) ущербно — компилятор и так знает типы и может проверить их, и это запутывает программиста».
Контрольные вопросы
Глава 9. Модель "Сущность-связь"(ER - Entity Relationship)
Инфологическая модель применяется на втором этапе проектирования БД, то есть после словесного описания предметной области. Процесс проектирования требует обсуждений с заказчиком, со специалистами в предметной области. Следовательно, инфологическая модель должна включать такое формализованное описание предметной области, которое легко будет "читаться" не только специалистами по базам данных. И это описание должно быть настолько емким, чтобы можно было оценить глубину и корректность проработки проекта БД и не должно быть привязано к конкретной СУБД. Проблема представления семантики давно интересовала разработчиков, и в семидесятых годах было предложено несколько моделей данных, названных семантическими моделями. К ним можно отнести семантическую модель данных, предложенную Хаммером (Hammer) и Мак-Леоном (McLeon) в 1981 году, функциональную модель данных Шипмана (Shipman), также созданную в 1981 году, модель "сущность—связь", предложенную Ченом (Chen) в 1976 году, и ряд других моделей. У всех моделей были свои положительные и отрицательные стороны, но испытание временем выдержала только последняя. И в настоящий момент именно модель Чена "сущность—связь", или "Entity Relationship", стала фактическим стандартом при инфологическом моделировании баз данных. Общепринятым стало сокращенное название ER-модель, большинство современных CASE-средств содержат инструментальные средства для описания данных в формализме этой модели. Кроме того, разработаны методы автоматического преобразования проекта БД из ER-модели в реляционную, при этом преобразование выполняется в даталогическую модель, соответствующую конкретной СУБД. Все CASE-системы имеют развитые средства документирования процесса разработки БД, автоматические генераторы отчетов позволяют подготовить отчет о текущем состоянии проекта БД с подробным описанием объектов БД и их отношений как в графическом виде, так и в виде готовых стандартных печатных отчетов, что существенно облегчает ведение проекта. В настоящий момент не существует единой общепринятой системы обозначений для ER-модели и разные CASE-системы используют разные графические нотации, но разобравшись в одной, можно легко понять и другие нотации. Как любая модель, модель "сущность—связь" имеет несколько базовых понятий, которые образуют исходные кирпичики, из которых строятся уже более сложные объекты по заранее определенным правилам. Эта модель в наибольшей степени согласуется с концепцией объектно-ориентированного проектирования, которая в настоящий момент, несомненно, является базовой для разработки сложных программных систем. В основе ER-модели лежат следующие базовые понятия:
Рис.1. Пример определения сущности в модели ER
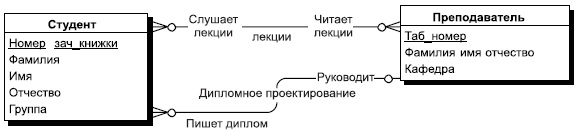
Рис. 2. Пример отношения "один-ко-многим" при связывании сущностей "Студент" и "Преподаватель" Связи делятся на три типа по множественности: один-к-одному (1:1), один-ко-многим (1:M), многие-ко-многим (M:M). Связь один-к-одному означает, что экземпляр одной сущности связан только с одним экземпляром другой сущности. Связь 1: M означает, что один экземпляр сущности, расположенный слева по связи, может быть связан с несколькими экземплярами сущности, расположенными справа по связи. Связь "один-к-одному" (1:1) означает, что один экземпляр одной сущности связан только с одним экземпляром другой сущности, а связь "многие-ко-многим" (M:M) означает, что один экземпляр первой сущности может быть связан с несколькими экземплярами второй сущности, и наоборот, один экземпляр второй сущности может быть связан с несколькими экземплярами первой сущности. Например, если мы рассмотрим связь типа "Изучает" между сущностями "Студент" и "Дисциплина", то это связь типа "многие-ко-многим" (M:M), потому что каждый студент может изучать несколько дисциплин, но и каждая дисциплина изучается множеством студентов. Такая связь изображена на рис. 3.
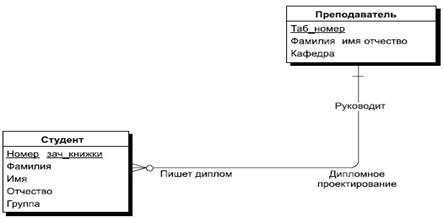
Рис. 3. Пример моделирования связи "многие-ко-многим" Между двумя сущностями может быть задано сколько угодно связей с разными смысловыми нагрузками. Например, между двумя сущностями "Студент" и "Преподаватель" можно установить две смысловые связи, одна — рассмотренная уже ранее "Дипломное проектирование", а вторая может быть условно названа "Лекции", и она определяет, лекции каких преподавателей слушает данный студент и каким студентам данный преподаватель читает лекции. Ясно, что это связь типа многие-ко-многим. Связь любого из этих типов может быть обязательной, если в данной связи должен участвовать каждый экземпляр сущности, необязательной — если не каждый экземпляр сущности должен участвовать в данной связи. При этом связь может быть обязательной с одной стороны и необязательной с другой стороны. Обязательность связи тоже по-разному обозначается в разных нотациях. В нотации POWER DESIGNER необязательность связи обозначается пустым кружочком на конце связи, а обязательность - перпендикулярной линией, перечеркивающей связь. И эта нотация имеет простую интерпретацию. Кружочек означает, что ни один экземпляр не может участвовать в этой связи. А перпендикуляр интерпретируется как то, что по крайней мере один экземпляр сущности участвует в этой связи. Рассмотрим для этого ранее приведенный пример связи "Дипломное проектирование"(рис.3). На нашем рисунке эта связь интерпретируется как необязательная с двух сторон. Но ведь на самом деле каждый студент, который пишет диплом, должен иметь своего руководителя дипломного проектирования, но, с другой стороны, не каждый преподаватель должен вести дипломное проектирование. Поэтому в данной смысловой постановке изображение этой связи изменится и будет выглядеть таким, как представлено на рис. 4.
Кроме того, в ER-модели допускается принцип категоризации сущностей. Это значит, что, как и в объектно-ориентированных языках программирования, вводится понятие подтипа сущности, то есть сущность может быть представлена в виде двух или более своих подтипов — сущностей, каждая из которых может иметь общие атрибуты и отношения и/или атрибуты и отношения, которые определяются однажды на верхнем уровне и наследуются на нижнем уровне. Все подтипы одной сущности рассматриваются как взаимоисключающие, и при разделении сущности на подтипы она должна быть представлена в виде полного набора взаимоисключающих подтипов. Если на уровне анализа не удается выявить полный перечень подтипов, то вводится специальный подтип, называемый условно ПРОЧИЕ, который в дальнейшем может быть уточнен. В реальных системах бывает достаточно ввести подтипизацию на двух-трех уровнях. Сущность, на основе которой строятся подтипы, называется супертипом. Любой экземпляр супертипа должен относиться к конкретному подтипу. Для графического изображения принципа категоризации или типизации сущности вводится специальный графический элемент, называемый узел-дискриминатор, в нотации POWER DESIGNER он изображается в виде полукруга, выпуклой стороной обращенного к суперсущности. Эта сторона соединяется направленной стрелкой с суперсущностью, а к диаметру этого круга стрелками подсоединяются подтипы данной сущности ( рис. 5).
Эту диаграмму можно расшифровать следующим образом. Каждый тест в некоторой системе тестирования является либо тестом проверки знаний языка SQL, либо некоторой аналитической задачей, которая выполняется с использованием заранее написанных Java-апплетов, либо тестом по некоторой области знаний, состоящим из набора вопросов и набора ответов, предлагаемых к каждому вопросу. В результате построения модели предметной области в виде набора сущностей и связей получаем связный граф. В полученном графе необходимо избегать циклических связей — они выявляют некорректность модели.
Пример построения ER-модели
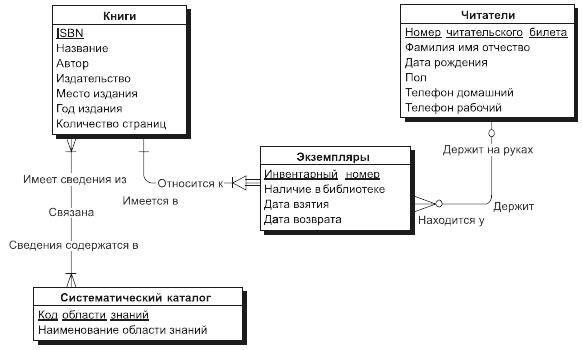
В качестве примера спроектируем инфологическую модель системы, предназначенной для хранения информации о книгах и областях знаний, представленных в библиотеке. Разработку модели начнем с выделения основных сущностей. Прежде всего, существует сущность "Книги", каждая книга имеет уникальный шифр, который является ее ключом, и ряд атрибутов, которые взяты из описания предметной области. Множество экземпляров сущности определяет множество книг, которые хранятся в библиотеке. Каждый экземпляр сущности "Книги" соответствует не конкретной книге, стоящей на полке, а описанию некоторой книги, которое дается обычно в предметном каталоге библиотеке. Каждая книга может присутствовать в нескольких экземплярах, и это как раз те конкретные книги, которые стоят на полках библиотеки. Для того чтобы отразить это, мы должны ввести сущность "Экземпляры", которая будет содержать описания всех экземпляров книг, которые хранятся в библиотеке. Каждый экземпляр сущности "Экземпляры" соответствует конкретной книге на полке. Каждый экземпляр имеет уникальный инвентарный номер, однозначно определяющий конкретную книгу. Кроме того, каждый экземпляр книги может находиться либо в библиотеке, либо на руках у некоторого читателя, и в последнем случае для данного экземпляра указываются дополнительно дата взятия книги читателем и дата предполагаемого возврата книги. Между сущностями "Книги" и "Экземпляры" существует связь "один-ко-многим" (1:М), обязательная с двух сторон. Чем определяется данный тип связи? Мы можем предположить, что каждая книга может присутствовать в библиотеке в нескольких экземплярах, поэтому связь "один-ко-многим". При этом если в библиотеке нет ни одного экземпляра данной книги, то мы не будем хранить ее описание, поэтому если книга описана в сущности "Книги", то по крайней мере один экземпляр этой книги присутствует в библиотеке. Это означает, что со стороны книги связь обязательная. Что касается сущности "Экземпляры", то не может существовать в библиотеке ни одного экземпляра, который бы не относился к конкретной книге, поэтому и со стороны "Экземпляры" связь тоже обязательная. Теперь необходимо определить, как в системе будет представлен читатель. Естественно предложить ввести для этого сущность "Читатели", каждый экземпляр которой будет соответствовать конкретному читателю. В библиотеке каждому читателю присваивается уникальный номер читательского билета, который будет однозначно идентифицировать нашего читателя. Номер читательского билета будет ключевым атрибутом сущности "Читатели". Кроме того, в сущности "Читатели" должны присутствовать дополнительные атрибуты, которые требуются для решения поставленных задач, этими атрибутами будут: "Фамилия Имя Отчество", "Адрес читателя", "Телефон домашний" и "Телефон рабочий". В сущности "Читатели" надо ввести обязательный атрибут "Дата рождения", который позволит контролировать возраст читателей. Каждый читатель может держать на руках несколько экземпляров книг. Для отражения этой ситуации надо провести связь между сущностями "Читатели" и "Экземпляры". А почему не между сущностями "Читатели" и "Книги"? Потому что читатель берет из библиотеки конкретный экземпляр конкретной книги, а не просто книгу. А как же узнать, какая книга у данного читателя? А это можно будет узнать по дополнительной связи между сущностями "Экземпляры" и "Книги", и эта связь каждому экземпляру ставит в соответствие одну книгу, поэтому мы в любой момент можем однозначно определить, какие книги находятся на руках у читателя, хотя связываем с читателем только инвентарные номера взятых книг. Между сущностями "Читатели" и "Экземпляры" установлена связь "один-ко-многим", и при этом она не обязательная с двух сторон. Читатель в данный момент может не держать ни одной книги на руках, а с другой стороны, данный экземпляр книги может не находиться ни у одного читателя, а просто стоять на полке в библиотеке. Теперь нам надо отразить последнюю сущность, которая связана с системным каталогом. Системный каталог содержит перечень всех областей знаний, сведения по которым содержатся в библиотечных книгах. Мы можем вспомнить системный каталог в библиотеке, с которого мы обычно начинаем поиск нужных нам книг, если мы не знаем их авторов и названий. Название области знаний может быть длинным и состоять из нескольких слов, поэтому для моделирования системного каталога мы введем сущность "Системный каталог" с двумя атрибутами: "Код области знаний" и "Название области знаний". Атрибут "Код области знаний" будет ключевым атрибутом сущности. Каждая книга может содержать сведения из нескольких областей знаний, а с другой стороны, из практики известно, что в библиотеке может присутствовать множество книг, относящихся к одной и той же области знаний, поэтому необходимо установить между сущностями "Системный каталог" и "Книги" связь "многие-ко-многим", обязательную с двух сторон. Действительно, в системном каталоге не должно присутствовать такой области знаний, сведения по которой не представлены ни в одной книге нашей библиотеки, противное было бы бессмысленно. И обратно, каждая книга должна быть отнесена к одной или нескольким областям знаний для того, чтобы читатель мог ее быстрее найти. Инфологическая модель предметной области "Библиотека" представлена на рис. 6.
Рис. 6. Инфологическая модель "Библиотека" Инфологическая модель "Библиотека" разработана нами под те задачи, которые были перечислены ранее. В этих задачах мы не ставили условие хранения истории чтения книги, например, с целью поиска того, кто раньше держал книгу и мог нанести ей вред. Если бы мы ставили перед собой задачу хранения и этой информации, то инфологическая модель была бы другой. Инфологическая модель используется на ранних стадиях разработки проекта. Если понимать язык условных обозначений, которые соответствуют категориям ER-модели, то ее можно легко "читать", следовательно, она доступна для анализа программистам-разработчикам, которые будут разрабатывать отдельные приложения. Для ER-модели существует алгоритм однозначного преобразования ее в реляционную модель данных, что позволило в дальнейшем разработать множество инструментальных систем, поддерживающих процесс разработки информационных систем, базирующихся на технологии баз данных. И во всех этих системах существуют средства описания инфологической модели разрабатываемой БД с возможностью автоматической генерации той даталогической модели, на которой будет реализовываться проект в дальнейшем. Выводы |
|