|
|
Распределенная обработка информацииПервоначальные информационные системы, основанные на базах данных, имели строго централизованную архитектуру. Данные были сосредоточены физически и логически на одном компьютере. Централизованная организация базы данных позволяет облегчить обеспечение ее безопасности, целостности и непротиворечивости. Вместе с тем рост объема базы данных и числа пользователей, получающих к ней доступ, территориальное развитие организации (и связанная с ней необходимость распределенной обработки данных) приводят к возникновению ряда проблем, свойственных централизованной архитектуры: - большой объем обмена данными (высокий трафик); - снижение надежности обмена данными; - снижение общей производительности; - рост затрат на разработку базы данных. Возможным решением перечисленных проблем является организация децентрализованного хранения данных. При децентрализации достигается: - параллельная обработка данных и распределение нагрузки; - повышение эффективности обработки данных при выполнении удаленных запросов; - уменьшение затрат на обработку данных; - упрощение процедуры управления информационной системы. Распределенная база данных – это набор отношений, хранящихся в разных узлах компьютерной сети и логически связанных таким образом, чтобы составлять единую совокупность данных. Распределенная база данных предполагает хранение данных на нескольких узлах сети, обработку данных и передачу между этими узлами в процессе выполнения запросов. Разбиение данных в распределенной базе данных может достигаться путем хранения различных таблиц на разных компьютерах или даже хранения разных частей и фрагментов одной таблицы на разных компьютерах. Для пользователя (или прикладной программы) не должно иметь значения, каким образом распределены данные между компьютерами. Работать с распределенной базой данных, если она действительно распределенная, следует так же, как и с централизованной, т. е. размещение базы данных должно быть прозрачно. Несмотря на то, что распределенная база данных состоит из нескольких локальных баз данных, у пользователя должна сохраняться иллюзия работы с централизованной базой данных, что вызывает потребность в использовании некоторого общего представления о данных – глобальной концептуальной схемы. Определение данных в такой концептуальной схеме должно быть аналогичным определению в централизованной базе данных. Отличия начинаются, когда требуется хранить данные в нескольких узлах. Чтобы произвести разбиение данных, нужно секционировать таблицы глобальной схемы на фрагменты. Существует два типа секционирования: горизонтальное и вертикальное. При секционировании таблицы но строкам выполняется горизонтальное секционирование, пои разбиении по столбцам – вертикальное. Таким образом, архитектура распределенной СУБД должна содержать информацию о секционировании исходных таблиц базы данных, что предполагает создание дополнительного уровня – фрагментного. Самый высший уровень архитектуры распределенной СУБД – это интерфейс прикладной программы и интерфейс процессора запросов. Для реализации и объяснения распределенной природы базы данных выделяются два уровня: фрагментный и уровень распределенного представления. Последний показывает географическое распределение данных по рабочим станциям, расположение экземпляра каждого фрагмента. 1–4 уровни архитектуры распределенной СУБД относятся к сетевой СУБД. Однако выделяют еще локальные СУБД, где определяют представление данных на каждой рабочей станции. Каждый уровень поддерживает различные представления базы данных; каждый уровень взаимодействует только со смежными уровнями представления. К. Дейт установил 12 свойств или качеств идеальной распределенной базы данных: 1. Локальная автономия.Локальная автономия означает, что управление данными на каждом из узлов распределенной системы выполняется локально. База данных, расположенная на одном из узлов, является неотъемлемым компонентом распределенной системы. Будучи фрагментом общего пространства данных, она в то же время функционирует как полноценная локальная база данных; управление ею выполняется локально и независимо от других узлов системы. 2. Независимость узлов. Независимость от центрального узла означает, что в идеальной системе все узлы равноправны и независимы, а расположенные на них базы являются равноправными поставщиками данных в общее пространство данных. База данных на каждом из узлов самодостаточна: она включает полный собственный словарь данных и полностью защищена от несанкционированного доступа. 3. Непрерывность операции. Непрерывные операции можно трактовать как возможность непрерывного доступа к данным (известное «24 часа в течение суток, семь дней в неделю») в рамках DDB вне зависимости от их расположения и вне зависимости от операций, выполняемых на локальных узлах. Это качество можно выразить лозунгом «данные доступны всегда, а операции над ними выполняются непрерывно». 4. Прозрачность расположений. Прозрачность расположения означает полную прозрачность расположения данных. Пользователь, обращавшийся к DDB, ничего не должен знать о реальном, физическом размещении данных в умах информационной системы. Все операции над данными выполняются без учета их местонахождения, Транспортировка запросов к базам данных осуществляется устроенными системными средствами. 5. Прозрачная фрагментация. Прозрачная фрагментация трактуется как возможность распределенного (то есть на различных узлах) размещения данных, логически представляющих собой единое целое. Существует фрагментация двух типов: горизонтальная и вертикальная. Первая означает хранение строк таблицы на различных узлах (фактически, хранение строк одной логической таблицы в нескольких идентичных физических таблицах на различных узлах). Вторая означает распределение столбцов логической таблицы по нескольким узлам. 6. Прозрачное тиражирование. Прозрачность тиражирования (асинхронного в общем случае процесса переноса изменений объектов исходной базы данных в базы, расположенные на других узлах распределенной системы) означает, что тиражирование возможно и достигается внутрисистемными средствами. 7. Обработка распределенных запасов. Обработка распределенных запросов DDB трактуется как возможность выполнения операций выборки над распределенной базой данных, сформулированных в рамках обычного запроса на языке SQL. 8. Обработка распределенных транзакций. Обработка распределенных транзакции DDB можно трактовать как возможность выполнения операций обновления распределенной базы данных {INSERT, UPDATE, DELETE), не разрушающее целостность и согласованность данных. Эта цель достигается применением двухфазового или двухфазного протокола фиксации транзакций, ставшего фактическим стандартом обработки распределенных транзакций. Его применение гарантирует согласованное изменение данных на нескольких узлах в рамках распределенной, или глобальной транзакции. 9. Независимость от оборудовании. Независимость от оборудования означает, что в качестве узлов распределенной системы могут выступать компьютеры любых моделей и производителей – от майнфреймов до «персоналок». 10. Независимость от операционных систем. Независимость от операционных систем как качество вытекает из предыдущего и означает многообразие операционных систем, управляющих узлами распределенной системы. 11. Прозрачность сети. Прозрачность сети означает, чти спектр поддерживаемых конкретной СУБД сетевых протоколов не должен быть ограничением системы с распределенными базами данных. Данное качество формулируется максимально широко; в распределенной системе возможны любые сетевые протоколы, 12. Независимость от баз данных. Независимость от баз данных означает, что в распределенной системе могут мирно сосуществовать СУБД различных производителей, и возможны операции поиска и обновления в базах данных различных моделей и форматив. Важнейшую роль в технологии создания и функционирования распределенных баз данных играет технология «представлений». Представлением называется сохраняемый в базе данных авторизованный глобальный запрос на выборку данных. Авторизованность означает возможность запуска такого запроса только конкретно поименованным в системе пользователем. Глобальность заключается в том, что выборка данных может осуществляться из всей базы даны, в том числе из данных, расположенных на других узлах сети. На сегодняшний день выделяют три самостоятельных технологий распределенной обработки данных: - клиент-сервер; - реплицирования; - объектного связывания. Реальные распределенные информационные системы, как правило, построены на основе сочетания этих технологий. Системы на основе технологии клиент-сервер развились из первых централизованных многопользовательских систем на основе мэйнфреймов и получили наиболее широкое распространение в корпоративных информационных системах. При реализации данной технологии отступают от одного из основных принципов создания распределенных систем - отсутствия центрального узла. Принцип централизации хранения и обработки данных является базовым принципом технологии клиент-сервер. Под сервером в широком смысле понимается любая система, процесс, компьютер, владеющие каким-либо вычислительным ресурсом (памятью, временем процессора, файлами и т.д.). Клиентом называется любая система, процесс, компьютер, пользователь, делающие запрос к серверу на использование ресурса. Одним из важнейших преимуществ архитектуры клиент-сервер является снижение сетевого трафика при выполнении запросов. Клиент посылает запрос серверу на выборку данных, запрос обрабатывается сервером, и клиенту передается не вся таблица (как было бы в технологии файл-сервер), а только результат обработки запроса. Второе преимущество – возможность хранение так называемой бизнес-логики (например, правил ссылочной целостности или ограничений на значения данных) на сервере, что позволяет избежать дублирование кода в различных клиентских приложениях, использующих общую базу данных. К недостаткам следует отнести недостаточно высокую производительность из-за необходимости передачи по сети все-таки большого количества данных. Построение быстродействующих информационных систем обеспечивают технологии репликации данных. Репликой называют копию базы данных, размещенную на другом компьютером сети для автономной работы пользователей. Основная идея репликации состоит в том, что пользователи работают автономно с общими данными, растиражированными по локальным базам данных. Производительность работы системы повышается из-за отсутствия необходимости обмена данными по сети. Для реализации технологии репликации программное обеспечение СУБД дополняется функциями тиражирования данных, их структуры, системной информации, информации о конфигурировании распределенной системы. Унификация взаимодействия прикладных компонентов с ядром информационных систем в виде SQL-серверов, наработанная для клиент-серверных систем позволила выработать аналогичные решения и по интегрированию разрозненных локальных баз данных под управлением настольных СУБД. Такая технология получила название объектного связывания данных, решающая задачу обеспечения доступа из одной локальной базы данных, открытой одним пользователем, к другой локальной базы данных, возможно, находящейся на другом компьютере, открытой другим пользователем. Решение этой задачи основывается на поддержке современными настольными СУБД технологии объектов доступа к данным – DAO (Data Access Objects). Под объектом понимается интеграция данных и методов их обработки в одно целое, на чем, как известно, основываются технологии объектно-ориентированного программирования. 11.8 Общие вопросы разработки баз данных СУБД Access
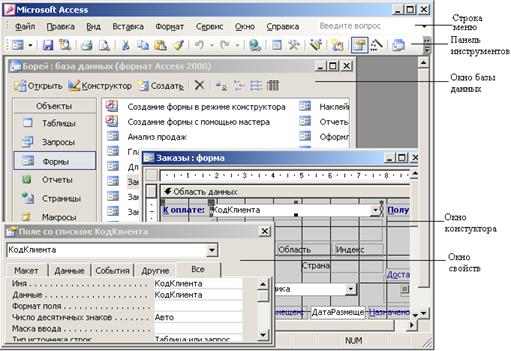
Рабочая среда Access Интегрированная среда Access предназначена для простого, логичного представления на экране информации базы данных и иных объектов, используемых при разработке приложения, а также для работы с имеющимися приложениями. После запуска Access из Windows (меню Пуск„ Программы „Microsoft Access) и открытия базы данных пользователь видит интерфейс интегрированной среды. На рисунке 66 представлены элементы интегрированной среды Access, которые непосредственно после запуска не все видны.
Рисунок 66 – Интерфейс в режиме конструктора форм
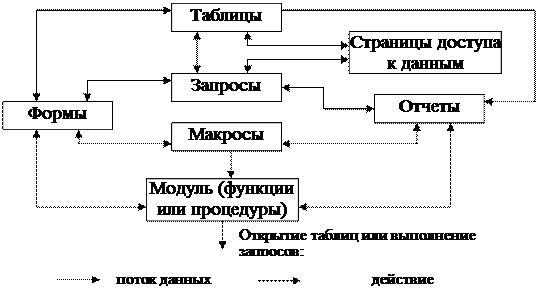
Концепция базы данных Части базы данных располагаются не по отдельности, а все вместе. Данные хранятся в таблицах и могут вводиться в них непосредственно или с использованием форм. Таблицы могут быть связаны одна с другой, а для извлечения нужных данных из одной или нескольких таблиц применяются запросы. Формы и отчеты основываются на запросах, которые позволяют как формам, так и отчетам отображать данные из двух или более таблиц. Концепция взаимосвязи объектов приведена на рисунке 67.
Рисунок 67 – Взаимосвязи основных объектов в Microsoft Access
Таблицы являются основным хранилищем данных. Данные состоят из записей (строк) и полей (столбцов). Поле – это категория информации, такая как имя или адрес, а запись – набор полей, характеризующих некоторый объект, например, данные о сотруднике. Форма является удобным средством для ввода и поиска информации в таблицах. Запрос получает требуемую информацию из одной и более таблиц. Это механизм выборки, обновления, удаления и добавления данных, создания новых таблиц на основании одной или нескольких таблиц. Отчет является организованным представлением данных из таблицы или запроса и предназначен для печати. В отчетах могут подводиться итоги, при этом выполняется обработка по заданному алгоритму. Макрос представляет собой способ структурированного описания одного или нескольких действий, которые автоматически выполняются в ответ на определенное действие. Модуль – это программы на языке Visual Basic, с помощью которых определенный процесс разбивается на несколько небольших процедур. Страницы доступа к данным – это файлы HTML и вспомогательные файлы для доступа к данным из MS Internet Explorer к данным базы данных.
|
|