|
|
Текст как поле статистического анализа.Сначала надо принять несколько основополагающих принципов процесса построения и проведения частотного статистического анализа текста и его отдельных признаков, как актуализированных и формализованных операций. При всей их очевидности, тем не менее, частенько они теряют свою приоритетность и тем самым уходят на второй план и становятся как бы незначимыми в актуальном понимании. Но значимыми они остаются объективно, что и заставляет исследователя следовать этим принципам.
Оставаясь вне поля формализованных активных статистических действий, тем не менее они хорошо воспринимаются на интуитивном уровне, т.е. объект как бы подразумеваются во всей его понятийной полноте. Так интуитивно с ними и работают на всех последующих этапах анализа первичной статистической информации.
Почему-то считается, что если в качестве признака какого-то смысла взято слово, например, офицер, то должно быть понятно всем, что под этим подразумевается. Но это далеко не так, из-за чего, чаще всего, и возникают различные смысловые недоразумения и приходится нередко, а точнее, чаще всего, тратить не мало времени и сил, что бы договориться о едином понимании используемого слова как признака и слова как понятия.
Ниже перечислены только основные принципы процесса построения и проведения частотного статистического анализа текста, которым необходимо следовать в обязательном порядке, причем следовать осознанно, превратив это знание в формализованное и актуализированное.
Теперь несколько слов о сущности именно того объекта, который собственно и интересует статистику, а соответственно, и исследователя в процессе проведения частотного статистического анализа текста. Речь идет о таком специфическом объекте как «частотное распределение», и имеющий свое самостоятельное значение как объект. Или, другими словами, о том как часто тот или иной признак, (так же выступающий как самостоятельный объект), проявляется в неком статистическом поле.
Надо сказать, что чаще всего факт «частотное распределение» признака не описывается в литературе как самостоятельный и формализованный объект, и в таком качестве актуально не воспринимается исследователями. Но интуитивно в таком качестве всегда рассматривался, причем во всех работах по статистике и иной соответствующей литературе Это происходило потому, что иначе его нельзя рассматривать как объект исследования.
Как мы уже говорили, в качестве признака может выступать какой-то его физический носитель. В качестве такого физического носителя может выступать: 1. Любое отдельное слово; 2. Словосочетание, т.е. слова, которые непосредственно следуют друг за другом; 3. Словосочетание, разделенные другими словами, т.е. разделенные каким-то текстовым пространством; 4. Смысловая характеристика, выраженная сложным ансамблем распределенных каким-либо образом по тексту слов.
Понятно, о чем мы уже говорили, каждый такой физический носитель является, в свою очередь, самостоятельным объектоми, имеющий собственный смысл, который так же может интересовать исследователя в контент-анализе. И здесь имеется очень интересная и важная зависимость между исследуемым признаком по значимости и физическим носителем данной значимости как самостоятельным признаком.
Так вот именно частотное выражение физического носителя, выступающий физическим признаком, позволяет, в свою очередь, определить смысл данного «частотного распределения», по значимости. Другими словами, смысл такого объекта как «частотное распределение», заключается в уровне его значения, конечно, относительно других объектов «частотного распределения».
Так, если мы исследуем признак «офицер», как содержательную единицу, то последнее оказывается очень тесно связано со словом «офицер», как его физического носителя. Если признак проявляется часто, то он получает статус высокой значимости, если употребляется редко, то средней значимости, и если попадается в единичном выражении, то значимость его весьма небольшая. Соответственно, приписываемый ему смысл, получает свою значимость: или очень высокую, или среднюю или низкую, при необходимости можно использовать любую градацию.
Признак или есть или его нет. Но если он появился, то признак уже значим в проявлении смысла данного текста или его части. И только после его обозначения можно говорить о его значимости по уровню частотного распределения. Соответственно, если признак не присутствует в тексте, то его значимость в частотном распределении нулевая, что тоже может иметь смысл, как мы уже отмечали, при определенных смысловых ситуациях.
Более того, в определенном смысле, можно даже рассматривать, так называемую «неявную» значимость частотного распределения. То есть явно признака нет в тексте, но он по контексту должен или может присутствовать. Теснота связи реального контекста с таким неявным признаком может быть потенциально очень высокая. И в этом случае сам текст или понятие могут получить иную интерпретацию.
Так, слово «фашизм», (этот пример, довольно часто рассматривается в научной литературе по контент-анализу), может не присутствовать в тексте, и даже сам текст не быть связанной с фашистской темой, но интерпретация текста, тем не менее, может протекать в рамках содержания понятия «фашизм». Но речь идет об особой интерпретации текста в рамках установленного понятия или же интерпретация понятия в рамках установленного контекста как доминанты. Такую интерпретацию можно назвать косвенным контент-анализом.
Речь в данном случае идет вот о чем. Как мы уже говорили, любой признак, если он введен в текст, в обязательном порядке имеет свой физической носитель, т.е. слово или словосочетание, простое или сложное. Если текст скрыто посвящен, например, фашизму, то данное понятие может быть выражено не прямо, а опосредовано, т.е. может быть заменен своим каким-то смысловым эквивалентом, например, синонимом, но в обязательном порядке понимаемый, доступный по смыслу, возможным читателем. Таким образом до него доносится в определенном частотном распределении, используемый автором тот или иной аспект (как признак) понятие фашизм.
Чаще всего частотное распределение интересующего исследователя признака, слова или словосочетания выражается или в абсолютных данных или в процентных соотношениях. Например, столько то раз такое-то слово употребилось в тексте. Или же указывается на процентное выражение частотного распределения признака в тексте.
Но в любом случае понятие много или мало, приобретает смысл только в том случае, если они соотнесены с некой точкой отсчета, которая сознательно или интуитивно выбирается в качестве критерия качественной оценки. И другого пути нет. Так, например, оценочная частота слово «военный» может быть установлена только относительно какого-то другого слова, значимость которого уже известна.
Так, например, очень интересный по результатам контент-анализ посланий Президента РФ Федеральному собранию, чему будет посвящена последняя глава настоящей работы, показал, что слово «военный» как смысловой признак, используется несколько реже, чем словосочетание «правоохранительные органы». Так, слово «военный» использовался в посланиях 43 раза, а словосочетание «правоохранительные органы» – 76 раз, что позволяет провести их соотносительный анализ в установленных исследователем смысловых рамках.
Более того с необходимостью должен присутствовать и третий критерий, т.е. соотношение двух величин в неком общем для них контексте. В этом случае общий контекст выступает доминантой или постоянной величиной, а два других исследуемых значения выступают относительно константы переменными величинами. Правда одну из них исследователь может принять как некую постоянную величину, но обязательно в рамках константы, а другую так же он обязан принять как переменную. Только при таком раскладе анализа приобретает смысл.
Так, слово «военный» в данном случае может быть переменной величиной, точнее его значимость как объекта частотного распределения. А понятие «правоохранительные органы» выступать некой постоянной величиной, как константой. Но их смысловое соотношение может устанавливаться только в рамках некоего общего понятия, например, «власть» как доминанты. Но выбор критерия сама по себе сложная задача и тема особого разговора.
Имеет смысл учитывать частотное распределение по частям текста, например, по важности того или иного блока. Наверно немаловажно, как часто проявляется тот или иной признак в блоке основных понятий или доминант. Так же, не менее важно уяснить, как часто проявляется признак в блоке вспомогательных слов. Возможно менее важно, но может быть весьма интересно, как часто проявляется признак в обслуживающих словах и словах-связках. Части текста или блоки, можно выстраивать по различным основаниям, сути не меняет. Важно, что бы они обеспечивали решения поставленной исследователем задачи.
Понятно, что процентное распределение признака относительно всех слов текста или части слов в отдельных блоках текста может быть весьма и весьма различным. А от этого зависит и его значимость в соответствии с уровнем частотного распределения. В одном блоке частотное распределение может быть не большим, но его значимость может быть высокой и наоборот, во второстепенных блоках, частотное распределение может быть очень высоким, но значимость низкой и т.д.
При необходимости можно говорить о блоке однопорядковых признаков, в частности, синонимов. В этом случае наполняемость основного признака будет большей. Иногда именно производные и сопутствующие признаки набирают большее число голосов, и соответствующим образом рисуют ту или иную картину. Поэтому ограничиваться только одним словом нередко бывает явно недостаточно.
Правда, отбор слов-признаков одного смыслового поля, к которому, в частности, относятся синонимы, представляет собой отдельную специальную процедуру, со своей методологией и методикой. Так, не все синонимы могут выступать носителями содержания статистического поля текста и быть использованы в этом случае для анализа. Так, понятию «военный» можно использовать синоним «военнослужащий», но нельзя в ряде случаев воспользоваться понятиями «война», «бранный», «ратный» и др.
Как мы уже говорили, частотное распределение само по себе не имеет смысла. И только относительно какого-то иного объекта, (частотного распределения признака), приобретает соответствующий смысл. Только в этом случае можно говорить о том, какое значение имеет исследуемый признак. Но это только первый и относительно простой шаг в статистическом анализе, использовании статистического аппарата.
В традиционном контент-анализе чаще всего используют именно простое частотное распределение в абсолютных или относительных величинах. Мало того, что такой явно простой, если не сказать больше, способ частотного анализа недостаточно информативен, процентные распределения частотного проявления признака, как правило, соотносят со всем частотным полем, более того без относительно его структуры и содержания. Все это прямиком ведет к искажению результатов, т.е. полученные данные не будут отражать ту объективную реальность, которую принялся анализировать исследователь.
Так слово «военный», (42 использования), относительно всего основного словарного состава текста (в посланиях, примерно 2500 основных слов) и относительно блока «армия», (210 использований), понятно имеют совершенно различное процентное распределение, а соответственно и различную смысловую интерпретацию.
Однако куда интереснее применить систему тесноты связи двух и более признаков по их частотному выражении. Другими словами, как часто употреблялось два или более, важных исследовательских признака (слова или словосочетания) и как тесно они между собой связаны. Так слово-признак «офицер» может быть тесно связано со словосочетание признаком «защитник Родины». Так же как оно может быть тесно связано с любым иным словом или словосочетанием как признаком, имеющим место быть в тексте.
Понятно, что теснота связи является весьма важной характеристикой смысла какой-либо доминанты или ключевого понятия. В зависимости от степени тесноты связи, основной признак может принимать различные смысловые значения, нередко прямо противоположные, (хотя контекст слова, как правило, этого не допускает). Однако при достаточно вольной интерпретации, (или не умелой), можно найти чего угодно, чем не редко и пользуются различные интерпретаторы, решая свои специфические профессиональные задачи. Но это уже тема особого разговора.
Определение тесноты связи достигается двумя путями: чисто интуитивно, прочитывая (и неоднократно) текст или же статистическими методами, тщательно просчитывая тесноту связи. В первом случае возможны и неизбежны не точности и большие погрешности, особенно в случае свободной интерпретации. Во втором случае, можно добиться относительно точных и по большей степени независимых от субъективизма исследователя результатов. А последнее по разным причинам всегда присутствует и нередко оказывает весьма сильное влияние на результаты контент-анализа.
Добиться определения статистической тесноты связи можно несколькими путями. Самое простое визуальное сопоставление процентных распределений интересующих исследователя признаков. Если два признака набрали большой процентный вес, по крайней мере сопоставимый, то можно утверждать наверняка, что между ними может быть зависимость и даже возможно присутствует причинно-следственная связь.
Если в тексте часто упоминается слово «офицер» и так же часто «защитник Родины», то наверно, можно утверждать, что слово «офицер» интерпретируется в рамках понятия «защитника Родины» или наоборот. Но для широкой и глубокой интерпретации связи этих двух признаков такого метода ее определения явно недостаточно. Хотя при определенных допущениях и решения не сложных задач, его можно применить вполне успешно.
Второй путь это использование статистических зависимостей с применением полного или неполного статистического аппарата. Например, использования простого парного распределения или корреляции в различных ее видах. Последнее позволяет определить довольно четко, насколько сильно связаны два выделенных показателя или же, наоборот, какие показатели имеют высокую степень корреляции. Парные распределения позволяют определить, в какой степени интересующий исследователя признак, присутствует или не присутствует в объекте.
Природа корреляционной зависимости представляет собой по сути характер или степень распределение одного признака, (или, как правило, его элемента, свойства), в другом объекте. Смотря, что берется за базу или доминанту. Теснота связи означает, что исследуемое качество доминирует в исследуемом объекте и он достаточно полно характеризует последнее в рамках исследуемых характеристик. В разделе «Логика контекстуального анализа» данной работы мы подробно об этом говорили.
Но здесь имеются два, (по меньшей мере), сильных ограничения. Первое то, что корреляционные связи не показывают причинно-следственных зависимостей. Корреляция только устанавливает тесноту зависимости и не более того. Все остальное, т.е. что от чего зависит, уже на совести или способностях интерпретатора. Так, например, слово «офицер» может быть тесно связанным с понятием «защитник Родины», но что является основой такой связи ответить в данном случае очень сложно.
Корреляционная связь безусловно должна содержать и содержит в себе какие-то причинно-следственные зависимости. Ведь если мы утверждаем, в том числе и при помощи статистического аппарата, что связь между данными явлениями существует, значит они каким-то образом зависят друг от друга. На практике, достаточно исследователю получить высокую корреляционную зависимость, как он сразу же интерпретирует ее в категориях причинно-следственной связи. И большое основание для этого у него, без сомнения, имеется.
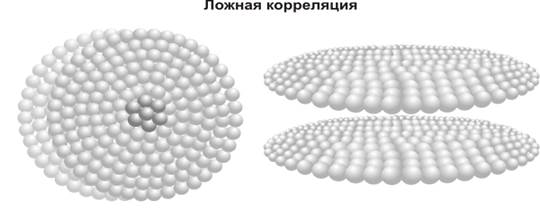
Второе ограничение и весьма существенное это, так называемая, ложная корреляция. Даже при высокой степени корреляционной зависимости, никогда нельзя сказать с полной уверенностью, что данная корреляция описывает реально существующую ситуацию, когда два явления обусловлены причинно-следственной зависимостью или же здесь наличествует «пустая» зависимость, не имеющая никакого реального наполнения. Просто математический аппарат посчитал некие параметры, так называемой, ложной корреляции.
Ложная корреляция есть самый настоящий бич для статистиков и не только для них. Никакой математической процедуры, определяющая параметры ложности или истинности корреляционной связи нет. Для того, что бы это определить требует сложные дополнительные исследования. Только в широком смысловом поле можно определить существуют ли причинно-следственные зависимости или нет. Но это требует больших усилий, и не всегда они оказываются по плечу исследователю.
Исследователи научились довольно эффективно избегать проблемы ложной корреляции: они просто перестали задавать самим себе и другим вопрос - ложная эта корреляция или истинная. Считается, что если корреляционная зависимость имеется, значит она истинная и ее можно интерпретировать. При этом добиваются нередко весьма интересной интерпретации. Ведь объяснить можно все, что хочешь, было бы желание и профессиональное умение.
Ложная корреляция возникает тогда, когда степень статистической связи является весьма высокой, а непосредственной причинно-следственной связи нет и чаще всего не может быть. В мире достаточно много таких явлений, когда по разным причинам какие-то случайные, опосредованные зависимости, вдруг неожиданно проявляются и путают все карты исследователям. Чаще всего и на самом деле они не имеют никакого отношения друг к другу, точнее они могут иметь весьма опосредованные связи. Статистики любят шутить по этому поводу.
Например, наблюдается большая статистическая зависимость между умершими людьми и потреблением огурцов и помидоров в свежем виде. На самом деле никакой существенной и тем более причинно-следственной связи нет. Высока частота наступления одного из событий, (потребления огурцов и помидоров в свежем виде), наложилась на константу - умершие люди в ее частотном выражении. В силу того, что многие люди любят и часто употребляют помидоры и огурцы в свежем виде, то естественно, этот признак оказался тесно связан со всеми теми людьми, их численностью, которые по какой-то причине умерли.
Еще один очень популярный пример, тесная связь между количеством аистов и численностью детей: от сюда вывод, что детей приносят аисты. Имеется тесная статистическая связь между фактами перебоев электричества в какой-либо деревне и большим количеством детей. Выводы читатель может сделать сам, в зависимости от той установки, которую он выберет в данной ситуации. Таких примеров можно набрать много.
Эти примеры показывают явно ложную корреляцию. Жизненный опыт, обыденное сознание подсказывают, что между этими и многими другими явлениями подобного рода наверняка нет никакой связи. Но имеется случаи и таковых так же не мало, когда уличить их в ложности практически не возможно. Более того имеется масса случаев, когда чаще всего не возможно ни при каких обстоятельствах утверждать, является ли она ложной или нет.
Так, например, нельзя однозначно утверждать, что между двумя такими явлениями как «офицер» и «защитник Родины» установлена именно истинная корреляция, так же как впрочем, нет никаких оснований утверждать и то, что она ложная. При всем при том, что корреляция может быть установлена очень хорошая. Однако, опять же жизненный опыт и здравый смысл показывает, что скорее всего причинно-следственная связь здесь имеется. На этом и остановимся и пускай об этом болит голова у самих статистиков.
Статистики, так же как и все смертные, нередко пользуются именно здравым смыслом, основывают свои выводы на жизненным опытом. Другое и вряд ли можно придумать в большинстве случаев. Можно сколько угодно долго исследовать, но вывод все равно приходится делать. Однако, статистики, и не только они, чаще всего тщательно скрывают, что их выводы основаны по преимуществу на здравом смысле и свои выводы выдают как результат долгой, кропотливой исследовательской работы.
Причин, обуславливающие ложную корреляцию, по всей видимости, много. Но чаще всего ложная корреляция это своеобразная вертикальная проекция относительно двух независимых по своей природе явления. Образно говоря, если на них посмотреть сверху, то появляется впечатление, причем полное, что они сильно связаны друг с другом. На самом деле «визуально», они просто наложились друг на друга. Но как только мы посмотрим «горизонтально», то сразу же будет видно, что это две плоскости событий, оказываются сильно или не очень сильно, но разделенными между собой в пространстве или во времени, а может быть и в том и в другом.
Так, в случае утверждения, что среди всех умерших, большинство употребляли помидоры и огурцы в свежем виде, произошло простое временное наложение двух плоскостей – «все умершие» и «потребляющие в свежем виде помидоры и огурцы». Первая плоскость как бы вобрала в себя вторую плоскость, если посмотреть на них так сказать «сверху». Но стоит изменить угол наклона «визуального» восприятия и сразу же становится ясно, что это две независимые плоскости. Жалко только, что нельзя продемонстрировать математически, поэтому приходится прибегать к образному представлению.
Определение корреляции как ложной или как истинной можно наверно только при одном условии, когда имеющая связь установлена в более общем для них контексте, истинность и ложность которого однозначно определена. Для этого очень эффективен метод факторного анализа и его вариации, при котором устанавливается корреляционная зависимость между рядом однопорядковых показателей. Если один из них или несколько показали слабую корреляцию, то имеется большое основание утверждать, что возможна причинно-следственная зависимость остальных и тем более основных признаков.
Так слово «служащий», имеет ряд синонимов, например, клерк, конторщик, работник, сотрудник, чиновник и пр. которые достаточно полно описывают данное смысловое поле. Так же как и имеются синонимы слова «защитник», (адвокат, апологет, борец, заступник, оборонитель, покровитель, страж и др.), которые так же хорошо описывают данное смысловое поле. Таким образом мы установили два смысловые поля с четко обозначенными показателями.
Если между явлениями «чиновник» и «защитник» не обнаружилось тесной корреляционной связи, то можно ее проверить на серии других корреляционных связей между их синонимами, которые могут подтвердить или не подтвердить исходный вывод. Правда, жизненный опыт подсказывает, как не крути и какой сложный статистический аппарата не применяй, связи здесь не найдешь никакой, поскольку ее в природе чиновничества не существует и не может существовать по определению. Так же как в смысловом поле «защитник» отсутствуют какие-либо элементы смыслового поля «чиновник».
В статистике используется еще один, очень хороший метод, это сжатие информации, что позволяет провести более четкое определение тренда или направления развития события, интересующего исследователя. При большой разбросанности признаков и их слабом проявлении, такой способ весьма впечатлителен. Хорош он даже при небольшой наполняемости признака. Обозначается данный метод словом коэффициент.
Коэффициентов в статистике описано довольно много, которые, чаще всего, характеризуют типовые тренды. Подстановка того или иного типового коэффициента (формулы расчета), позволяет быстро получить интересующий результат – есть ли тренд или нет, имеется ли тенденция или нет и в какую сторону он развивается и пр. Более того позволяет относительно просто автоматизировать процесс вычисления коэффициента и соответственно тренда. Система автопилот в самолете тому образец.
Так, если признаков смыслового поля «офицер» и смыслового поля «защитник Родины» мало, наполнение соответствующими понятиями (словами и словообразованиями), явно не достаточно для простого корреляционного ряда, тогда прибегают к сжатию информации. Выявляют серию специальных показателей, например, синонимов и устанавливая, например, их весовой коэффициент, например, по шкале значимости, можно довольно надежно утверждать, что связь между ними имеется и возможно очень хорошая.
Но применять его надо очень осторожно, ибо требует довольно четкой идентификации интересующих исследователя признаков. В противном случае есть опасность попадания в поле статистического анализа иных по содержанию признаков. При малой наполняемости это может быть роковым - получить неверный тренд. Но и при большой наполняемости частотного проявления признаков неприятностей не избежать: может возникнуть смещение признаков в смежном широком смысловом поле.
Другая реально существующая неприятность – определение содержания степени сжатия информации. Ее можно так сжать, что никого тренда не получишь, поскольку природа явления при этом может сильно измениться. Или же растянуть до неузнаваемости, когда статистическое поле будет, как говориться, «рваться», появятся «провалы», «выбросы» и пр., что может весьма сильно затруднит анализ.
Что бы избежать подобного варианта, необходимо сразу же условиться о степени сжатия, исходя из природы явления и решаемой задачи. Правда сделать это чаще всего оказывается возможным или в типовой ситуации, когда смысловое поле известно или же в результате многократных опытов и проигрывании на каких-либо моделях или уже проверка на практике. Приговор последней обжалованию уже не подлежит, и если что-то сделано не правильно, то исправить уже ничего нельзя и все придется начинать с начала.
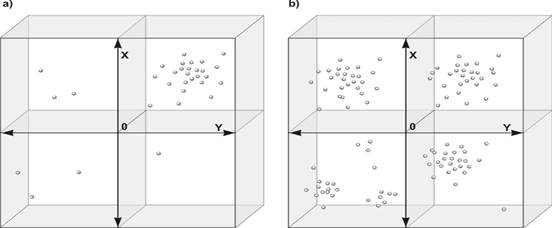
Наглядно этот процесс можно представить таким образом: если в неком визуальном статистическом поле, частотные точки признака сгруппировались в одном месте, в одном отсеке «шкафа», при допустимой статической погрешности, приведшей к небольшому разбросу, то тренд налицо и его можно спокойно описывать каким-либо приемлемым для данного случае коэффициентом. Если частотные точки группируются в разных позициях статистического поля, то, или же тренда нет, или же частотный анализ проведен не корректно. В статистике все это хорошо описано и показано.
Текст такое же статистическое поле как и любое другое. Если корреляционная зависимость слабая, то имеет смысл ввести дополнительные показатели, что бы усилить возможную зависимость и тем самым определить тренд. Так, зависимость между частотным проявлениям признака-слова «офицер» и частотным проявлениям признака-слова «защитник Родины» может быть по разным причинам слабая, но введя другие показатели данного смыслового поля, можно с большей или меньшей уверенностью или обоснованностью утверждать, что в тексте данная связь присутствует или ее нет.
В данном разделе, мы показали только самые общие моменты статистического анализа. Это особая область исследования, тем более, что практика статистического анализа текста, как особая область статистического анализа, точнее статистического анализа особого рода реальности, может подсказать и особые статистические приемы анализа, как это бывает с иными областями объективной реальности, куда добралась статистика. Но об этом в следующей главе.
Методика контент-анализа |
|