|
|
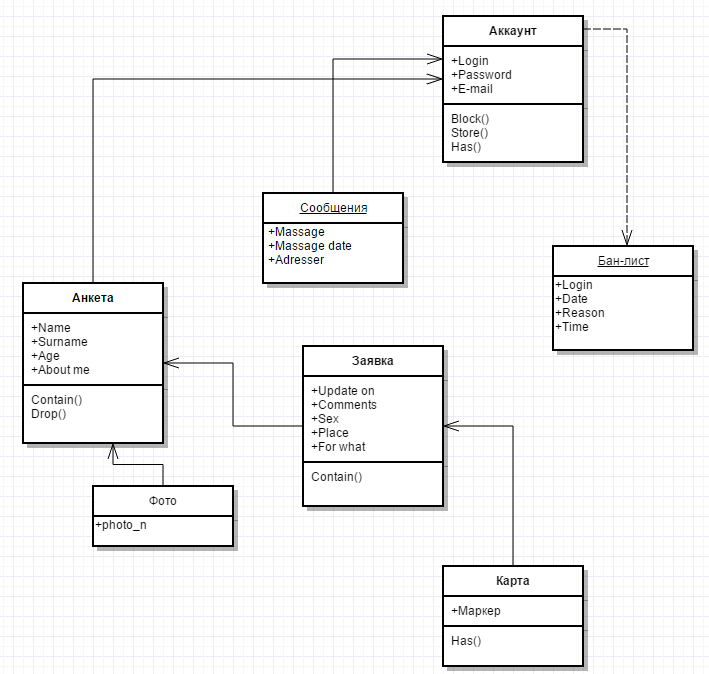
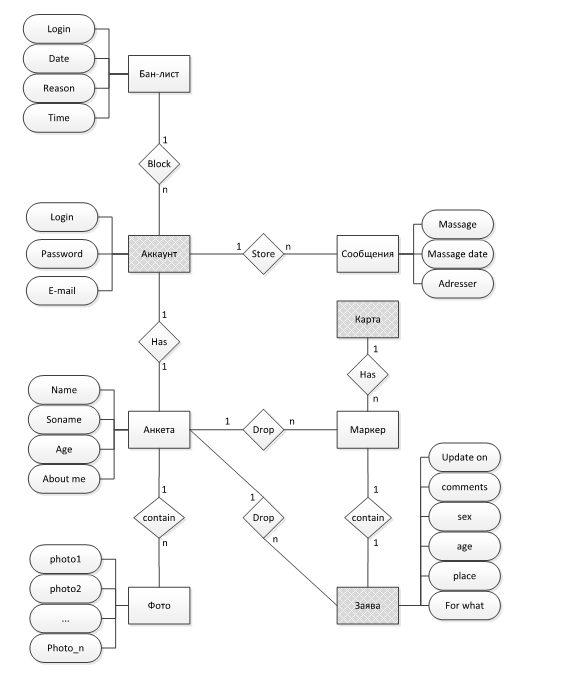
Программная реализация алгоритма для серверной части системыВзаимодействие клиента с сервером основана на обмене сообщениями определенного формата с помощью сетевого канала. Во избежание формирования ложных сообщений, были выведены неколько конструкторов для различных типов сообщение с ограниченными комбинациями тегов из основных enum. Структура стандартного сообщения выглядит следующим образом: · Параметр; · Действие; · Значения. Для ограничения возможных опций создания сообщения используется связка из private классов и статических методов для создания их объектов. То есть, программист не может создать экземпляр сообщения непосредственно, минуя статические методы, а значит и формирования сообщения с неверными параметрами исключено. Часто разработчики выносят этот функционал на графический интерфейс, однако подход по отделению логики от GUI зарекомендовал себя как более надежный, поэтому реализация была имплементирована именно таким образом. Передача ведется через интерфейс соккет из пакета. Сервер «слушает» канал на возникновение новых подключений и после этого, в случае их возникновения, создает отдельный поток для каждого, чтобы получение несколько сообщений, одновременно не прерывая работы программы и не вызывая коллизий или Дедлок. Кроме того, в приложении реализован серьезной защите от доступа посторонних, что представляет из себя фабрику сертификатов и AES шифрования сообщений. На рисунке 9 представлена реляционная модель базы данных web-ориентированной информационной системы оценки меню пользователя, состоящая из таких сущностей как:
Рисунок 9 – Реляционная модель базы данных web-ориентированной информационной системы Был разработан метод поиска неявных сообществ пользователей социальных сетей на основе социальных связей между ними. Предложенный алгоритм локально имитирует человеческое общение между парами индивидуумов, а глобально моделирует инфекционный процесс. Основой алгоритма является процесс обмена метками сообществ между вершинами в соответствии с динамическими правилами взаимодействия, в ходе которого поощряется объединение сообществ ближайших контактов отдельных пользователей в глобальные сообщества. Дополнительным шагом алгоритма является определение сообществ с недостаточной внутренней связанностью и разделение их на более связные подсообщества. Разработанный метод обладает следующими особенностями: · применимость к ориентированным и неориентированным графам; · учёт весов на рёбрах; · поиск как пересекающихся, так и непересекающихся сообществ; · поиск как локальных (среди ближайших контактов пользователя), так · и глобальных сообществ; · низкая вычислительная сложность; · возможность распределённой реализации в рамках вычислительной · модели Pregel. Все этапы, за исключением первого, выполняются отдельно для каждого атрибута, что схематически изображено на рисунке 10. На этапе построения исходного набора данных производится сбор данных пользователей из сети Twitter. Для каждого пользователя сначала запрашивается только его профиль в сети Twitter. При наличии в нём ссылки на профиль того же пользователя в сети Facebook (в которой набор пользовательских атрибутов существенно больше, чем в Twitter) запрашиваются и сохраняются все доступные сообщения пользователя из сети Twitter.
Рисунок 10 – Система обработки сообщений После чего для текущего пользователя запрашивается и сохраняется его профиль в сети Facebook, из которого извлекаются указанные пользователем значения его атрибутов. На этапе предварительной обработки текста к текстам полученного на предыдущем этапе набора данных применяется метод определения языковой принадлежности текста. После этого данные пользователей распределяются в различные наборы данных в зависимости от языка пользователя (рисунок 11). Кроме того, на этом этапе осуществляется фильтрация сообщений, авторство которых не принадлежит пользователю (ретвиты). Поскольку цитирование сообщений других пользователей является весьма популярным способом распространения информации в сети Twitter, этот шаг предварительной обработки особенно важен для повышения точности метода.
Рисунок 11 – Дамп базы данных Таким образом, элементом набора данных для каждого атрибута и языка является набор символьных строк, полученных из текстов сообщений и 2 профиля одного пользователя в Twitter, а также значение атрибута у данного пользователя в Facebook. На этапе построения признакового описания из сообщений пользователей извлекаются лингвистические признаки. Из полученных токенов строится набор признаков в виде N-грамм размером от 1 до 3 с учётом порядка токенов. Каждый тип признаков представлен двумя подтипами: с учётом и без учёта регистра символов. Итоговый вектор признаков для пользователя является бинарным, то есть содержит только информацию о наличии или отсутствии признака в его текстовых данных. Количество экземпляров одного признака игнорируется. На этапе отбора информативных признаков применяется метод, основанный на расчёте условной взаимной информации. Производится итеративный отбор тех признаков, которые содержат наибольшее количество информации о значении атрибута и при этом существенно отличаются от признаков, выбранных на предыдущих итерациях. Таким образом, каждый признак результирующего набора высоко информативен и слабо зависит от остальных признаков. На этапе обучения производится построение модели классификации с использованием онлайнового пассивно-агрессивного алгоритма [10]. На этапе классификации в качестве входных данных используются тексты сообщений и поля профиля произвольного пользователя. Выполняется алгоритм классификация для заданного языка и атрибута. Результатом является значение атрибута выбранного пользователя. Для тестирования использовались наборы данных англоязычных пользователей Twitter, размеченные по полу (мужской/женский), возрасту (моложе 20 лет/от 20 до 40 лет/старше 40 лет), семейному положению (состоит/не состоит в отношениях), политическим (демократ/республиканец) и религиозным (христианин/мусульманин/атеист) взглядам. Для оценки качества результатов используется точность классификации (accuracy). Исходный набор данных разделяется на обучающую и тестовую подвыборки. В качестве входных данных используются тексты пользователей сети Twitter из тестовой подвыборки исходного набора данных. Тестирование метода с использованием сообщений на других языках (русский, английский, испанский, немецкий, французский, итальянский, португальский, корейский, китайский) показало похожие результаты. В общем случае качество результатов во многом зависит от размера обучающего набора данных и его сбалансированности по значениям атрибутов. Поиск описаний событий Сообщения пользователей социальных сетей составляют существенную долю текстового контента современного Веба. Кроме того, социальные сети зачастую выступают в роли неформальных СМИ, где любой пользователь может опубликовать новостное сообщение о происходящих событиях (информационных поводах).
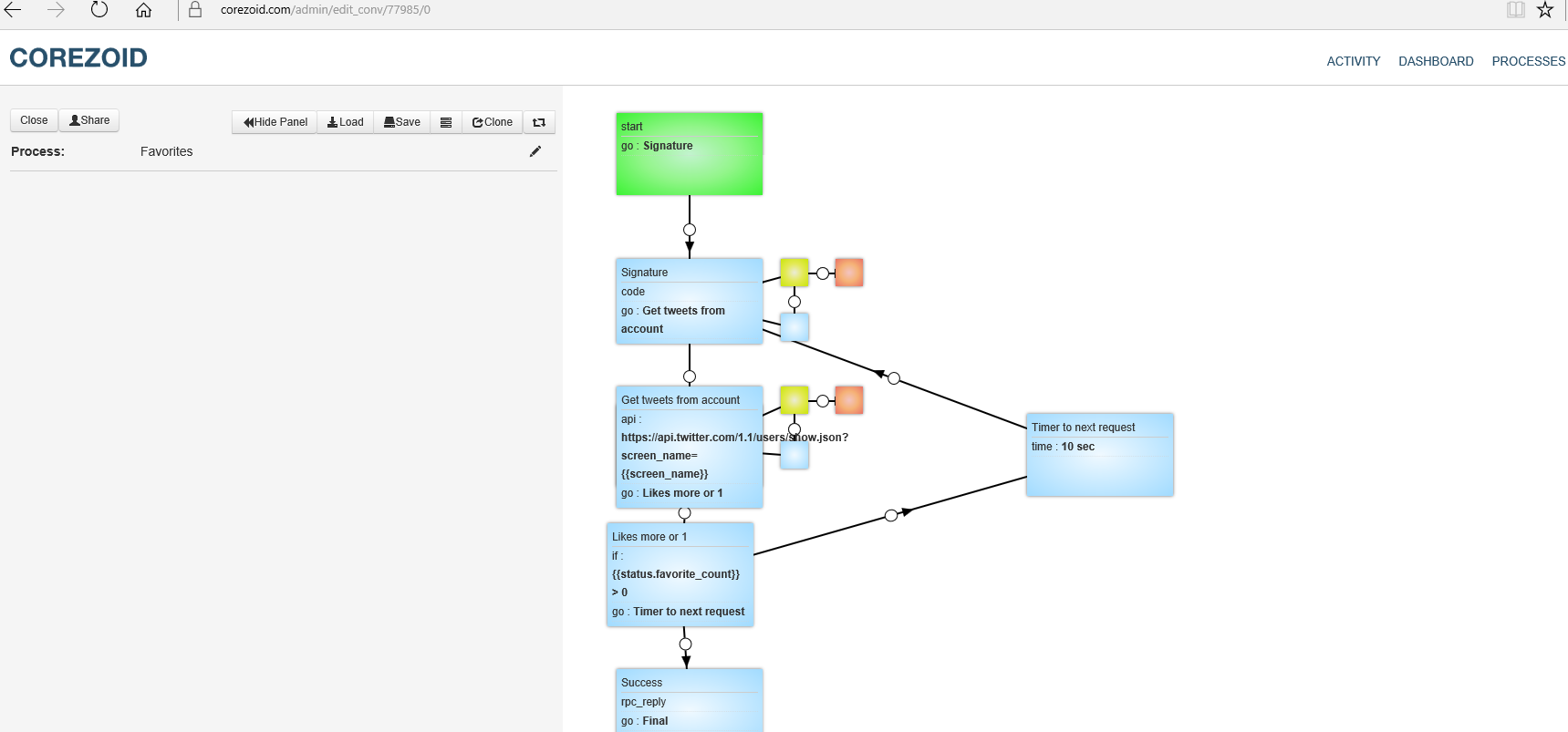
ER-модель базы данных, интегрированной с алгоритмом показана на рисунке 12.
Рисунок 12 – ER-модель базы данных Алгоритмическая модель в системе Corezoid показана на рисунке 13.
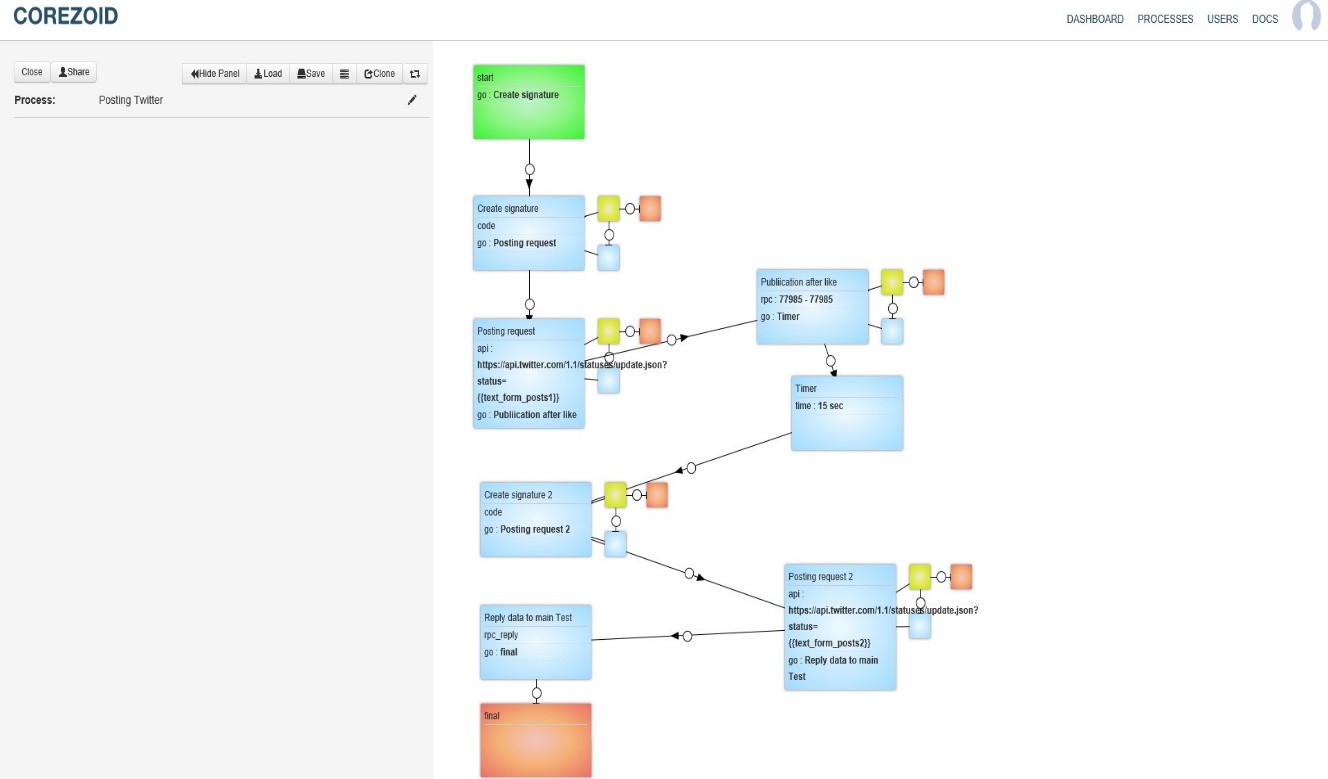
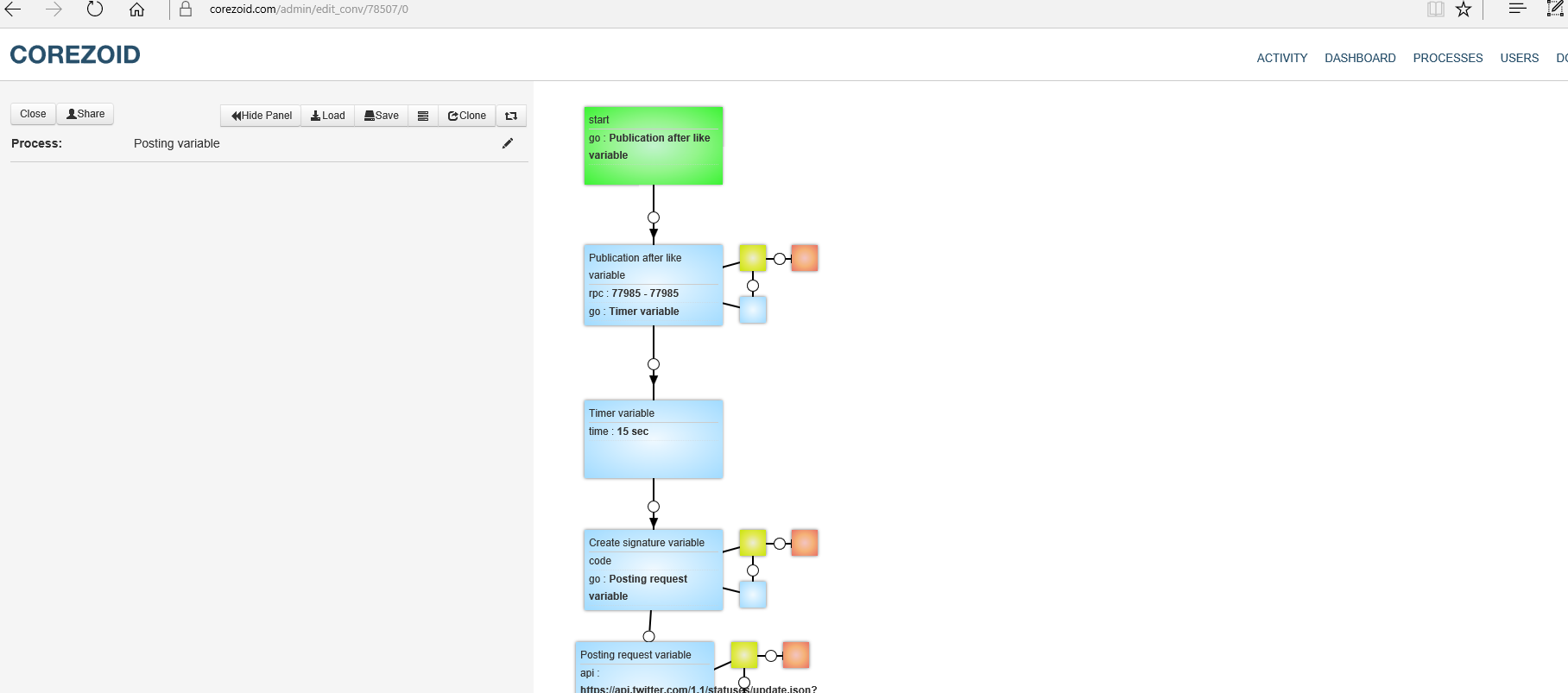
Рисунок 13 – Алгоритмическая модель в системе Corezoid Главная задача серверного механизма – обеспечение публикации нового поста в аккаунте пользователя, когда предыдущий пост был отмечен «лайком» любым пользователем социальной сети, что отображено на главной алгоритмической ветви на рисунке 14.
Рисунок 14 – Главная алгоритмическая ветвь |
|