|
|
Описание результатов экспериментаАнализ данных может быть получен как в автоматическом режиме так и в ручном. Программа может сама проанализировать собранную информацию и представить в наглядном виде. Эта возможность реализована по следующим категориям: В результате работы приложения, полученная информация обрабатывается, после чего представляется в удобном виде. Категории, по которым автоматически обрабатывается информация: возраст, пол, местонахождение, образование, модель поведения в социальных медиа. Если возникает необходимость получить анализ любого другого направления, например, род занятий, интересы, потребительские предпочтения, цели пользования Интернетом и т.д., тогда необходим определенный порядок действий: • загрузить базу данных XML с сервера на локальный компьютер; • импортировать XML в Microsoft Access, используя штатный механизм Access; • с помощью средств Microsoft Access сделать выборку; • обработать выборку с помощью Microsoft Access или Microsoft Excel. Для обработки данных с Microsoft Access можно использовать и любые другие программные средства, которые могут быть полезными для других задач. В общем информация внутри XML базы данных хранятся в таком виде: <UserInfo> <Код> 1 </ Код> <id_vk> 1702950 </ id_vk> <Name> Батырбек </ Name> <SecondName> Айналимов </ SecondName> <BD> 27.05.1990 </ BD> <Sex> 1 </ Sex> <Contry> Россия </ Contry> <City> Волжский </ City> <Param1> 1 </ Param1> ... <Param20> 5 </ Param20> </ UserInfo>
Но мешая убыточности XML файлов и их большой размер, теги максимально сокращены, отсутствуют атрибуты, а дополнительные параметры сгруппированы в одно поле, которое отсутствует для записей, описывающих пользователя, который не прошел анкетирование. Таким образом конечный XML файл выглядит следующим образом: <? xml version = "1.0" encoding = "UTF-8"?> <dataroot xmlns: od = «urn: schemas-microsoft-com: officedata» xmlns: xsi = "http://www.w3.org/2001/XMLSchema-instance» xsi: noNamespaceSchemaLocation = «XML2.xsd» generated = " 2012-05-08T00: 20: 51 "> <o> <Код> 1 </ Код> <i> 1702950 </ i> <n> Батырбек </ n> <s> ч </ s> <b> 1990-05-27 </ b> <c> Россия </ c> <t> Вожский </ t> <p> 10101001011101010135 </ p> </ o> </ dataroot>
Генеральная совокупность. Суммарная численность объектов наблюдения (людей), обладающих определенным набором признаков (пол, возраст, род занятости, численность и т.д.), ограниченная в пространстве и времени Выборка (Выборочная совокупность). Часть объектов из генеральной совокупности, отобранных для изучения, с тем чтобы сделать вывод о всей генеральной совокупности. Для того чтобы вывод, полученное путем изучения выборки, можно было распространить на всю генеральную совокупность, выборка должна иметь свойство репрезентативности. Репрезентативность выборки. Свойство выборки корректно отображать генеральную совокупность. Одна и та же выборка может быть репрезентативной для разных генеральных совокупностей. Важно понимать, что репрезентативность выборки и ошибка выборки - разные явления. Репрезентативность, в отличие от ошибки никак не зависит от размера выборки. Ошибка выборки (доверительный интервал). Отклонение результатов, полученных с помощью выборочного наблюдения от истинных данных генеральной совокупности. Ошибка выборки бывает двух видов - статистическая и систематическая. Статистическая погрешность зависит от размера выборки. Чем больше размер выборки, тем она ниже. Обычно, когда говорят об ошибке выборки, имеют в виду именно статистическую ошибку. Систематическая ошибка зависит от различных факторов, постоянное влияние на исследования и смещая результаты исследования в определенную сторону. В некоторых случаях, когда известны истинные распределения, систематическую ошибку можно нивелировать введением квот или перевешивания данных, но в большинстве реальных исследований также оценить ее бывает довольно проблематично. Выборки делятся на два типа: • Вероятностные • Невероятностные 1. Вероятностные выборки 1.1 Случайная выборка (простой случайный отбор). Такая выборка предполагает однородность генеральной совокупности, одинаковую вероятность доступности всех элементов, наличие полного списка всех элементов. При отборе элементов, как правило, используется таблица случайных чисел. 1.2 Механическая (систематическая) выборка. Разновидность случайной выборки, упорядоченная по какому-либо признаку (алфавитный порядок, номер телефона, дата рождения и т.д.). Первый элемент отбирается случайно, затем, с шагом 'n' отбирается каждый 'k'первый элемент. Размер генеральной совокупности, при этом - N = n * k 1.3 стратифицированная (районированная). Применяется в случае неоднородности генеральной совокупности. Генеральная совокупность разбивается на группы (страты). В каждой казни отбор осуществляется случайным или механическим образом. 1.4 Серийная (гнездовая или кластерная) выборка. При серийной выборке единицами отбора выступают не сами объекты, а группы (кластеры или гнезда). Группы отбираются случайным образом. Объекты внутри групп обследуются сплошь. 2. Невероятностные выборки. Отбор в такой выборке осуществляется не по принципам случайности, а по субъективным критериям - доступности, типичности, равного представительства и т.д. 2.1. Квотная выборка. Сначала выделяется определенное количество групп объектов. Для каждой группы задается количество объектов, которые должны быть обследованы. Количество объектов, которые должны попасть в каждую из групп, задается, чаще всего, или пропорционально заранее известной частью группы в генеральной совокупности, или одинаковым для каждой группы. Внутри групп объекты отбираются произвольно. Квотные выборки используются в маркетинговых исследованиях достаточно часто. 2.2. Метод снежного кома. Выборка строится следующим образом. У каждого респондента, начиная с первого, просятся контакты его друзей, коллег, знакомых, которые подходили бы под условия отбора и могли бы принять участие в исследовании. Таким образом, за исключением первого шага, выборка формируется с участием самих объектов исследования. Метод часто применяется, когда необходимо найти и опросить труднодоступные группы респондентов (например, респондентов, которые имеют высокий доход, респондентов, принадлежащих к одной профессиональной группы, респондентов, которые имеют какие-либо похожие хобби / увлечения и т.д.) 2.3 Стихийная выборка. Опрашиваются наиболее доступные респонденты. Типичные примеры стихийных выборок - опрос в газетах / журналах, анкеты, отданные респондентам на самозаполнение, большинство интернет-опросов. Размер и состав стихийных выборок заранее не известен, и определяется только одним параметром - активностью респондентов. 2.4 Выборка типичных случаев. Отбираются единицы генеральной совокупности, обладающих средним (типичным) значением признака. При этом возникает проблема выбора признаки и определения его значения по умолчанию. При ручной обработке информации может использоваться любой из методов. Ошибка выборки (доверительный интервал). Интервал, исчисленный по выборочным данным, который с заданной вероятностью (доверительной) накрывает неизвестное истинное значение оцениваемого параметра распределения. Автоматически подсчитываются каждый раз, когда выводятся результаты анализа. Для ее подсчеты необходимы следующие данные: • Доверительная вероятность. Вероятность того, что доверительный интервал накроет неизвестное истинное значение параметра оценивается по выборочным данным. В практике исследований используется 95% -ную доверительная вероятность • Размер генеральной совокупности. Обозначать его как А. • Размер выборки. Обозначать его как В. • Доля признаки (вариативность). Ожидаемая доля признаки, для которого рассчитывается ошибка. Обозначать ее как С. Отдельного внимания заслуживает анализ информации о модели поведения пользователей в социальных медиа, типология такого исследования основана на особенностях пользования социальных медиа. Исследование может буди полезным для многих целей. Также на основе него можно судить о будущем социальных медиа, тенденций, моделей дальнейшего развития. Каждая из моделей поведения подразумевает определенный перечень действий, пользователь делает чаще всего. Таким образом выделяются сегменты активных и малоактивных пользователей по модели поведения. Среди малоактивных наименее активными являются пользователи с периферийными целями, активнее - с целью обучения, самыми активными - потребители контента. Среди активных трудно определить кто является более активным, кто менее. Активность аудитории определяется не количество пользователей, относится к каждой из моделей поведения, а другие факторы, связанные с созданием, потреблением и распространением информации пространством социальных медиа. Методика определения наличия у пользователя определенной модели поведения предполагает, что каждой из моделей характерен определенный набор действий. Для каждого действия подсчитывается количество пользователей, ее делают, и подсчитывается относительно общего количества пользователей. В каждой из моделей преобладают определенные действия. По тем действиям, которые во пользователя и определяется его модель поведения в социальных медиа. Количество пользователей Интернет - 43% от населения страны, а пользователей социальных сетей 87% от количества пользователей Интернета (по данным на 2014 г.). Если рассматривать пользователей социальной сети «Twitter» как выборку, а пользователей Интернета как генеральную совокупность, то можно сказать, что выборка является репрезентативной, и вполне соответствует генеральной совокупности. Именно факт репрезентативности пользователей социальных медиа и пользователей Интернета в России позволяет проводить подобного рода анализ, проводимый в работе. В результате работы приложения, полученная информация обрабатывается, после чего представляется в удобном виде. Данные можно ограничивать временными промежутками. Категории, по которым обрабатывается информация: • возраст; • пол; • уровня образования; • места учебы; • места жительства; • сообществ, в которых он значится; • модели поведения; • частоты пользования социальными медиа; • места и средства пользования социальными медиа; • ответов на вопросы анкеты; • род занятий; • интересы; • потребительские предпочтения; • цели пользования Интернетом. После этого получать статистику по заданным параметрам или динамику изменений. Потребность в такой информации может появиться у определенного круга специалистов: • маркетологам (используя данные относительно пола, возраста, уровня образования, места учебы, места жительства, сообществ, модели поведения, частоты пользования социальными медиа, места и средств пользования социальными медиа, ответов на вопросы анкеты) • социологам (используя данные относительно пола, возраста, уровня образования, места учебы, места жительства, модели поведения); • журналистам (используя данные относительно пола, возраста, уровня образования, места учебы, места жительства, сообществ, модели поведения, ответов на вопросы анкеты) • для статистики (используя данные относительно пола, возраста, уровня образования, места учебы, места жительства, сообществ, модели поведения, частоты пользования социальными медиа, места и средств пользования социальными медиа) • разработчикам (используя данные о модели поведения, частоты пользования социальными медиа, места и средств пользования социальными медиа, ответов на вопросы анкеты). Перейдем к апробации интерфейса системы многопоточного расспределенного постинга с применением генетического и динамического алгоритмов выбора свободного сервера Twitter. Для этого авторизируемся в разработаной социальной сети и перейдем на вкладку «Мои Заметки» (рисунок 28).
Рисунок 28 – Мои Заметки
Авторизируемся в системе (рисунок 29).
Рисунок 29 – Авторизация в системе
Авторизируемся в Twitter (рисунок 30).
Рисунок 30 – Авторизация в системе Twitter
Нажмем кнопку «Добавить сообщение», чтобы подготовить формы для ввода трех постов (рисунок 31).
Рисунок 31 – Добавление нового поля ввода
Введем текст постов и дополнительно загрузим 500 постов через Dashboard системы Corezoid (рисунок 32).
Рисунок 32 – Ввод текста сообщений Нажмем кнопку «Публиковать» (рисунок 33).
Рисунок 33 – Публикация сообщений Дейстивтельно, публикация первых постов происходила после «лайка» каждого предыдущего поста (рисунок 34).
Рисунок 34 – Публикация первых постов Пятьсотый пост также был успешно опубликован спустя неделю, когда пользователь поставил лайк на предыдущем посте (рисунок 35).
Рисунок 35 – Публикация последних постов Нагрузочное тестирование системы было выполнено в течение недели после публикации первого поста. Для этого была измерена нагрузка на центральный процессор сервера в течение публикации 500 постов. Полученный график нагрузки отображен на рисунке 36.
Рисунок 36 – Нагрузка на центральный процессор сервера публикаций Corezoid Как видно из графика, изображенного на рисунке 36, суммарная суточная нагрузка на центральный процессор при публикации 500 сообщений не превышает 1 cp, а соответственно стоит отметить эффективность генетического алгоритма постинга сообщений. В результате проведенной апробации были получены ожидаемые результаты. Отклонений в работе системы относительно рассчетных данных не выявлено. Выводы по четвёртой главе В результате проведенной апробации был проведен практический расчет эффективности работы системы по алгоритмам, применённым для решения задачи. Практическая часть тестирования основывалась на создании и успешном выполнении тестовой публикации медиа-плана. В течение всего периода тестирования оценивались показатели качества интерфейса системы. Анализ выражений 2.1 – 2.8 свидетельствует, что их условно можно разделить на два типа: "жесткие". Нарушение "жестких" условиях приводит к распределению, который не может быть реализован физически, поэтому значение функции приспособленности для этого случая равна нулю и соответствующая особь в дальнейшем исключается из расчетов. Нарушение "мягких" условиях приводит к ситуации, когда распределение может быть реализован физически, однако задачу по отношению к соответствующему объекту не будет выполнено. Поэтому для таких объектов функция локальной эффективности принудительно устанавливается равной нулю, однако соответствующие особи с дальнейшей эволюции не исключаются и могут выступать родителями для формирования следующего поколения. Такую регулятивную функцию и выполняет коэффициент kj. Общее количество генов в хромосоме соответствует количеству объектов поражения. Каждый ген содержит значение количества боевых единиц, назначаются на соответствующий объект. Такая структура хромосомы отвечает полиалельному варианта генетического алгоритма (ГА), который и был использован для решения задачи. Процесс оптимизации заключается в многократном генерировании (по некоторым правилам) вариантов векторов независимых переменных и определении для значений функции приспособленности. За оптимальное решение принимается вектор переменных, которому соответствует наибольшее значение функции среди всех рассчитанных. Для проверки возможности практического использования разработанного подхода в среде программирования была создана серверная программа, которая позволяет решать задачу оптимизации с помощью ГА. Отбор "отцов" для скрещивания осуществлялся по турнирной схеме с двумя участниками. Формирование следующего поколения осуществлялось по элитной схеме, когда лучший генотип принудительно переносился в следующее поколение. Модификация генотипа осуществлялась с помощью равномерного кроссовера с вероятностью 0,9, мутации с вероятностью 0,95 и инверсии с вероятностью 0,2. Количество особей в популяции составляла 50, а количество поколений - 250. Время расчетов на ЭВМ Intel-166 – 0,57 с. Дополнительная настройка параметров ГА не производилась. Сравнение результатов расчетов по этим методам свидетельствует, что использование ГА позволило найти более эффективный вариант распределения, чем метод динамического программирования (в данном случае, на 1,6%), что свидетельствует о потенциально высокой вычислительной эффективности ГА. Заключение Каждый год появляется множество как универсальных, так и нишевых социальных сервисов и для активных пользователей Интернет типично иметь несколько профилей в различных социальных сетях. Несмотря на то, что существуют попытки по обеспечению единого способа взаимодействия между различными социальными платформами (например, OpenSocial3), они не получили широкого применения, а новые социальные сервисы продолжают появляться. Идентификация пользователя в различных социальных сетях позволяет получить более полную картину о социальном поведении данного пользователя в сети Интернет. Обнаружение аккаунтов, принадлежащих одному человеку, в нескольких социальных сетях, позволяет получить более полный социальный граф, что может быть полезно во многих задачах, таких как информационный поиск, интернет-реклама, рекомендательные системы и т.д. Поскольку поиск аккаунтов пользователя в различных сетях в общем случае требует наличия актуальных данных обо всех пользователях данных сетей, целесообразно ограничить пространство поиска ближайшими соседями какого-либо пользователя, аккаунты которого в исследуемых сетях известны. Таким образом, задача идентификации пользователей в различных социальных сетях в локальной перспективе подразумевает сопоставление аккаунтов пользователей в рамках списков контактов некоторого центрального пользователя в различных социальных сетях. Такая задача часто возникает при работе с контактами пользователей в социальных мета- сервисах, которые, в частности, могут служить для объединения новостных потоков в поддерживаемых социальных сервисах или предоставления единой системы обмена сообщениями. Подобная задача возникает также при использовании функции автоматического объединения контактов из различных источников (телефонная книга, социальные сети, мессенджеры), распространённой в современных мобильных устройствах. Был применен метод решения задачи идентификации пользователей Twitter, что сводится к возможности управления аккаунтом последнего для осуществления активности в виде новых сообщений с привязкой к условиям информационной среды. В рамках данной работы такими условиями являются время и интерес пользователей Twitter к опубликованному сообщению. Сформулированы актуальные направления дальнейших научных исследований в области разработки ИС и приложений БД. Разработанное программное обеспечение упрощает взаимодействия менеджера рекламного агентства с социальной сетью Twitter при решении задачи медиапланирования. Одной из доминирующих тенденций развития социальных сетей как социокультурного феномена является более глубокое понимание особенностей социального поведения человека и, как следствие, создание новых средств для самовыражения, а также обмена информацией и опытом. При этом наличие большого количества корпоративных аккаунтов у одной управляющей компании производит значительную нагрузку на менеджера рекламного агентства ввиду необходимости отслеживания интереса пользователей к публикациям. Облачные технологии привели к действительно революционных изменений в области информационных технологий и их использования во всех составляющих университетской жизни, развития учебного процесса, научно-технологических проектов, сотрудничества с ИТ-индустрией и индустрией высоких технологий вообще. Ученые, преподаватели, студенты не только успешно изучают и исследуют инструментарий облачных вычислений, но и принимают непосредственное участие в реальных разработках для аэрокосмической, транспортной, энергетической и других критических и коммерческих отраслей, где облачные ИТ-инфраструктуры. По этой причине в рамках выполнения бакалаврской работы было спроектировано и разработано программное обеспечение, автоматизирующие задачу отслеживания интереса пользователей Twitter к публикуемым сообщениям. Результатом отслеживания является публикация нового сообщения из медиаплана, когда интерес пользователей достигнет минимум один «лайк» в терминологии сети Twitter. Важно, что эти разработки направлены на совершенствование всех элементов коммерческого процесса, его динамической и рациональной информатизации с использованием частных и корпоративных облачных решений, предоставления образовательных, консалтинговых и инжиниринговых услуг. В бакалаврской работе получены следующие новые теоретические и практические результаты: · выполнено построение сигналов для каждого токена (последовательности символов) с использованием информации о частоте его появления в корпусе в различные моменты времени; · осуществлено применение вейвлетного анализа к полученным сигналам; · произведено удаление незначительных токенов с использованием автокорреляции сигналов; · выполняется построение матрицы кросс-корреляции сигналов токенов; · осуществляется поиск событий как наборов токенов путём кластеризации полученной матрицы; · выполняется поиск сообщений, описывающих каждое событие, с помощью метода мульти-документного реферирования по документам, содержащим токены из каждого набора. · программный продукт не требует данных о пользователях и доступа к внешним базам знаний; · реализована возможность инкрементальной обработки при поступлении новых сообщений по разработанному алгоритму. Если же веса ребер могут быть отрицательными, то необходимо применять алгоритм Беллмана-Форда, время работы которого О (nm). Если необходимо найти расстояния между всеми парами вершин графа, граф является разряженным и все ребра имеют неотъемлемые веса, то можно выполнить n раз алгоритм Дейкстры. Если же граф является разряженным, но в нем могут быть ребра с отрицательными весами, то необходимо использовать алгоритм Джонсона. Если необходимо найти расстояния между всеми парами вершин, веса ребер могут быть отрицательными и граф не является разряженным (m стремится к n2), то необходимо использовать алгоритм Флойда-Уоршола. Ни один из приведенных алгоритмов не может быть применен для графов, которые содержат негативные циклы. Однако алгоритм Беллмана-Форда (как и алгоритм Джонсона), а также алгоритм Флойда-Уоршола могут выявить такие циклы. Примененные алгоритмы поиска кратчайшего пути используются для эффективного выбора свободного и самого ближайшего сервера передачи и обработки данных. Разумно ожидать дальнейшего расширения пользовательской модели и функционала социальных сетей, что приведёт к появлению новых типов данных в виде объектов и связей социального графа и, как следствие, возможности более эффективно решать задачи, связанные с обработкой персональной информации. Сравнение результатов расчетов по этим методам свидетельствует, что использование генетического алгоритма позволило найти более эффективный вариант распределения, чем метод динамического программирования (в данном случае, на 1,6%), что свидетельствует о потенциально высокой вычислительной эффективности генетического алгоритма. Кроме рассмотренных вопросов, существует несколько научно-технологических задач, требующих решения. Это разработка систем управления облачными системами, для полноценной реализации эластичного масштабирования; совершенствование систем хранения и управления данными; внедрение универсальных средств разработки облачных приложений; тесная интеграция всех компонентов системы, приводит, в конечном итоге, к улучшению характеристик облачной системы. Список литературы
1) Gjoka M. et al. Practical recommendations on crawling online social networks. Selected Areas in Communications, IEEE Journal on. – 2011. – Т. 29. – №. 9. – С. 1872-1892. 2) Leskovec J., Faloutsos C. Sampling from large graphs. Proceedings of the 12th ACM SIGKDD international conference on Knowledge discovery and data mining. – ACM, 2006. – С. 631-636. 3) Najork M., Wiener J. L. Breadth-first crawling yields high-quality pages. Proceedings of the 10th international conference on World Wide Web. – ACM, 2001. – С. 114-118. 4) Васильев А.Н.: Java. - СПб.: Питер, 2011 5) Веселкова Т.В.: Эффективная эксплуатация сайта. - М.: Дашков и К, 2011 6) Грачев А.: Создаем свой сайт на WordPress. - СПб.: Питер, 2011 7) Гребенюк Е.И.: Технические средства информатизации. - М.: Академия, 2011 8) Громаковский А.: Работа с облачными системами удаленного доступа. - СПб.: Питер, 2011 9) Емельянова Н.З.: Проектирование информационных систем. - М: Форум, 2011 10) Заварыкин В.М., Житомирский В.Г., Лапчик М.П. Основы информатики и вычислительной техники. — М.: Просвещение, 1989. 11) Задачи по программированию / С. А. Абрамов, Г. Г. Гнездилова, Е. Н. Капустина, М. И. Селюн. — М.: Наука, 1988. 12) Зозуля Ю.Н.: Настройка компьютера с помощью BIOS. - СПб.: Питер, 2011 13) Касаткин В. Н. Информация. Алгоритмы. ЭВМ. — М.: Просвещение, 1991. 14) Культин Н.Б.: С/С++ в задачах и примерах. - СПб: БХВ-Петербург, 2011 15) Мезенцев К.Н.: Автоматизированные информационные системы. - М.: Академия, 2011 16) Михеева Е.В.: Информационные технологии в профессиональной деятельности. - М.: Академия, 2011 17) Негус Кристофер: Ubuntu и Debian Linux для продвинутых. - СПб.: Питер, 2011 18) НИУ БелГУ ; авт.-сост.: Н.А. Беседина, Ю.В. Францева ; рец.: Т.А. Клепикова, Т.М. Тимошилова: Английский язык для сферы компьютерных наук. - Белгород: ИПК НИУ БелГУ, 2011 19) НИУ БелГУ ; гл. ред. Л.Я. Дятченко: Научные ведомости Белгородского государственного университета. - Белгород: ИПК НИУ "БелГУ", 2011 20) Устинин Д.М., Коваленко И.Б., Ризниченко Г.Ю., Рубин А.Б. Сопряжение различных методов компьютерного моделирования в комплексной модели фотосинтетической мембраны. Компьютерные исследования и моделирование. 2013. Т. 5. № 1. C. 65–81. 21) Хрущев С.С., Абатурова А.М., Дьяконова А.Н., Устинин Д.М., Зленко Д.В., Федоров В.А., Коваленко И.Б., Ризниченко Г.Ю., Рубин А.Б. Моделирование белок-белковых взаимодействий с применением программного комплекса многочастичной броуновской динамики. Компьютерные исследования и моделирование. 2013. Т. 5. № 1. C. 47–51. Приложения ПРИЛОЖЕНИЕ А – Схема проведения эксперимента
Слайд №1 – Обзор возможностей компьютерного моделирования.
Продолжение приложения А
Слайд №2 – Сравнительная характеристика алгоритмических моделей.
Продолжение приложения А
Слайд №3 – Обзор существующих систем распространения информации в социальных сетях.
Продолжение приложения А
Слайд №4 – Цели и задачи исследования.
Продолжение приложения А
Слайд №5 – Математическая модель распространения информации посредством «Twitter».
Продолжение приложения А
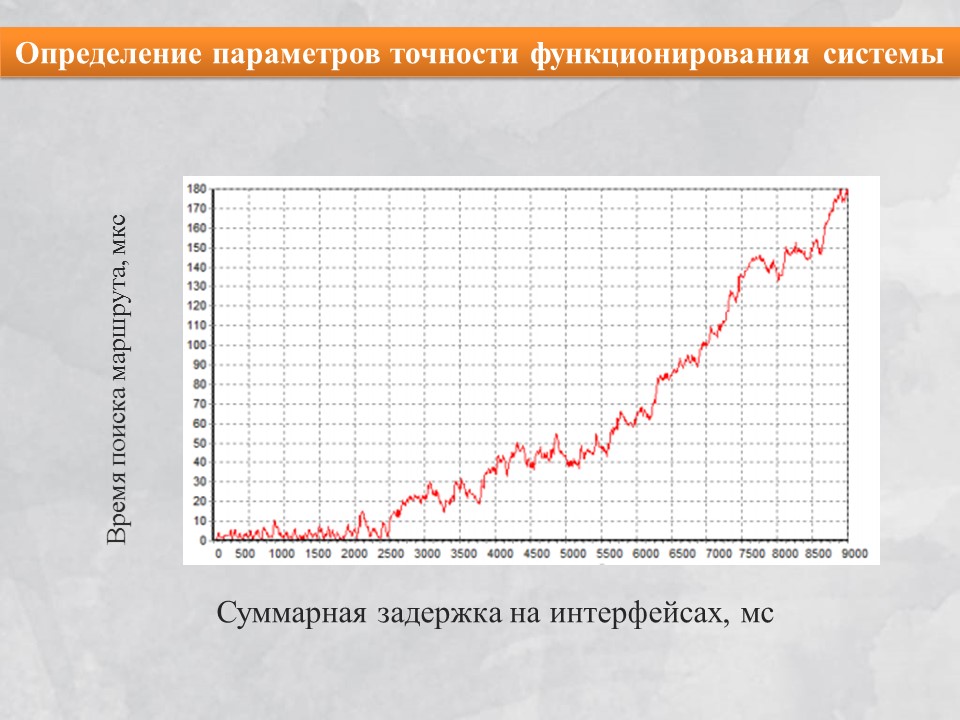
Слайд №6 – Определение параметров точности функционирования системы.
Продолжение приложения А
Слайд №7 – Проектирование клиент-серверного приложения для взаимодействия с социальной сетью «Twitter».
Продолжение приложения А
Слайд №8 – Алгоритм работы системы.
Продолжение приложения А
Слайд №9 – Алгоритм работы системы.
Продолжение приложения А
Слайд №10 – Алгоритм работы системы.
Продолжение приложения А
Слайд №11 – Алгоритм работы системы.
Продолжение приложения А
Слайд №12 – Проектирование базы данных.
Продолжение приложения А
Слайд №13 – Интерфейс приложения-клиента.
Продолжение приложения А
Слайд №14 – Интерфейс приложения-клиента.
Продолжение приложения А
Слайд №15 – Интерфейс приложения-клиента.
Продолжение приложения А
Слайд №16 – Интерфейс приложения-клиента.
Продолжение приложения А
Слайд №17 – Интерфейс приложения-клиента.
Продолжение приложения А
Слайд №18 – Интерфейс облачной операционной системы-сервера «Corezoid».
Продолжение приложения А
Слайд №19 – Интерфейс облачной операционной системы-сервера «Corezoid».
Продолжение приложения А
Слайд №20 – Интерфейс облачной операционной системы-сервера «Corezoid».
Продолжение приложения А
Слайд №21 – Интерфейс облачной операционной системы-сервера «Corezoid».
Продолжение приложения А
Слайд №22 – Интерфейс облачной операционной системы-сервера «Corezoid».
Продолжение приложения А
Слайд №23 – Анализ и апробация результатов.
Продолжение приложения А
Слайд №24 – Анализ и апробация результатов.
ПРИЛОЖЕНИЕ Б – Код файла Coresoid.php
<?php /** * Corezoid Module * * NOTICE OF LICENSE * * This source file is subject to the Open Software License (OSL 3.0) * that is available through the world-wide-web at this URL: * http://opensource.org/licenses/osl-3.0.php * * @category Corezoid * @package Corezoid/Corezoid * @version 1.0 * @author corezoid.com * @copyright Copyright (c) 2013 corezoid.com * @license http://opensource.org/licenses/osl-3.0.php Open Software License (OSL 3.0) * * EXTENSION INFORMATION * * Corezoid API http://www.corezoid.com/how_to_use/api/en/ * */ /** * Corezoid Class * * @author Corezoid <support@mcorezoid.com> */ class Corezoid { /** * host Corezoid
Продолжение приложения Б */ private $_host = 'https://www.corezoid.com'; /** * Version API */ private $_version = '1'; /** * Format API */ private $_format = 'json'; /** * User API */ private $_api_login; /** * API secret key */ private $_api_secret; /** * Array tasks */ private $_tasks = array(); /** * Constructor. * * @param string $api_login * @param string $api_secret * * @throws InvalidArgumentException */ public function __construct($api_login, $api_secret) { if (empty($api_login)) { throw new InvalidArgumentException('api_login is empty'); } if (empty($api_secret)) { throw new InvalidArgumentException('api_secret is empty'); Продолжение приложения Б }
$this->_api_login = $api_login; $this->_api_secret = $api_secret; } /** * Add new task * * @param string $ref * @param string $conv_id * @param array $data * * @throws InvalidArgumentException */ public function add_task($ref, $conv_id, $data = array()) { if (empty($ref)) { throw new InvalidArgumentException('ref is empty'); } if (empty($conv_id)) { throw new InvalidArgumentException('conv_id is empty'); } $this->_tasks[] = array( 'ref' => $ref, 'type' => 'create', 'obj' => 'task', 'conv_id' => $conv_id, 'data' => $data ); } /** * Send tasks to Corezoid * * @return string */ public function send_tasks() { Продолжение приложения Б $content = json_encode(array('ops' => $this->_tasks)); $time = time(); $url = $this->make_url($time, $content);
$ch = curl_init(); curl_setopt($ch, CURLOPT_URL, $url); curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false); curl_setopt($ch, CURLOPT_POST, 1); curl_setopt($ch, CURLOPT_POSTFIELDS,$content); curl_setopt($ch, CURLOPT_RETURNTRANSFER,1); $server_output = curl_exec($ch); curl_close($ch); return $server_output; } /** * Check Signature * * @param string $sign * @param string $time * @param string $content * * @return string */ public function check_sign($sign, $time, $content) { $make_sign = $this->make_sign($time, $content); return ($sign == $make_sign) ? true : false; } /** * Create URL to Corezoid * * @param string $time * @param string $content * * @return string */ private function make_url($time, $content) Продолжение приложения Б { $sign = $this->make_sign($time, $content); return $this->_host.'/api/' .$this->_version.'/' .$this->_format.'/' .$this->_api_login.'/' .$time.'/' .$sign; } /** * Create Signature * * @param string $time * @param string $content * * @return string */ private function make_sign($time, $content) { return $this->str2hex(sha1($time.$this->_api_secret.$content.$this->_api_secret, 1)); } /** * String to HEX * * @param string $str * * @return string */ private function str2hex($str) { $r = unpack('H*', $str); return array_shift( $r ); } } ?>
ПРИЛОЖЕНИЕ В – Код файла action.php // API user settings $api_login = '41294'; $api_secret = 'czwPIScyl7PHsdjEGLn67e8wysaOJpVIEz6tHEyR5MViMxJm4I';
// Init Middleware class $MV = new Corezoid($api_login, $api_secret);
// Add new task $ref1 = time().'_'.rand(); $task1 = array('text_form_posts1' => $text_form_posts1, 'text_form_posts2' => $text_form_posts2, 'oauth_token' => $oauth_token, 'oauth_token_secret' => $oauth_token_secret, 'text_form_posts3' => $text_form_posts3, 'text_form_posts4' => $text_form_posts4, 'text_form_posts5' => $text_form_posts5, 'text_form_posts6' => $text_form_posts6, 'text_form_posts7' => $text_form_posts7, 'text_form_posts8' => $text_form_posts8, 'text_form_posts9' => $text_form_posts9, 'text_form_posts10' => $text_form_posts10); // ID conveyor $conv_id = 77662;
$MV->add_task($ref1, $conv_id, $task1);
// Send all tasks to Middleware $res = $MV->send_tasks(); ?>
ПРИЛОЖЕНИЕ Г – Код файла index.php <!DOCTYPE html> <html lang="en"> <head> <meta charset="utf-8"> <meta http-equiv="X-UA-Compatible" content="IE=edge"> <meta name="viewport" content="width=device-width, initial-scale=1"> <title>Бакаларвская работа</title> <link href='http://fonts.googleapis.com/css?family=Varela+Round' rel='stylesheet' type='text/css'> <link href="css/bootstrap.min.css" rel="stylesheet"> <link href="http://netdna.bootstrapcdn.com/font-awesome/4.1.0/css/font-awesome.min.css" rel="stylesheet"> <link href="css/flexslider.css" rel="stylesheet" > <link href="css/styles.css" rel="stylesheet"> <link href="css/queries.css" rel="stylesheet"> <link href="css/animate.css" rel="stylesheet"> <!-- HTML5 Shim and Respond.js IE8 support of HTML5 elements and media queries --> <!-- WARNING: Respond.js doesn't work if you view the page via file:// --> <!--[if lt IE 9]> <script src="https://oss.maxcdn.com/libs/html5shiv/3.7.0/html5shiv.js"></script> <script src="https://oss.maxcdn.com/libs/respond.js/1.4.2/respond.min.js"></script> <![endif]--> <script src="http://ajax.googleapis.com/ajax/libs/jquery/1/jquery.min.js"></script> <script src="https://cdn.firebase.com/js/client/2.3.1/firebase.js"></script> </head> <body id="top"> <header id="home"> <nav> <div class="container-fluid"> <div class="row"> <div class="col-md-8 col-md-offset-2 col-sm-8 col-sm-offset-2 col-xs-8 col-xs-offset-2"> <nav class="pull"> Продолжение приложения Г <ul class="top-nav"> <!-- <li><a href="#intro">Introduction <span class="indicator"><i class="fa fa-angle-right"></i></span></a></li> --> |
|