|
|
Оценка фитнесс функции созданных правилФитнесс-функция подобного алгоритма многокритериальная и состоит из нескольких составляющих, объединяемых мультипликативно или аддитивно. Можно выделить два различных вида составляющих: · Точностные (отвечают за точность) · Форменные (отвечают за форму и качество правила) Точностные составляющие Критерием качества фитнесс-функции является оценка точности результатов. Наиболее распространенной оценкой является среднеквадратичная ошибка.
Где
Качество правила также можно оценить с помощью таблицы: ЕСЛИ А ТО С
A – все подусловия C – все подзаключения TP – true positive (число примеров, удовлетворяющих и А, и С) FP – false positive (число примеров удовлетворяющих А, но не совпадающих с С). Ошибка первого рода или неправильный прогноз FN – false negative (число примеров, не удовлетворяющих А, но удовлетворяющих С). Ошибка второго рода, возможный, но не реализованный прогноз. Если человек болен болезнью, но врач эту болезнь не диагностирует – мы имеем дело с ситуацией FN (ошибка второго рода). Если человек не болен болезнью, а врач эту болезнь нашел – FP (ошибка первого рода). Однозначно, ошибки и первого и второго рода являются нежелательными, но имеют различные последствия. TN – true negative (число примеров не удовлетворяющих ни А, ни С). Правильный отрицательный прогноз. Коэффициент, отвечающий за ошибки первого рода:
Коэффициент, отвечающий за ошибки второго рода:
Хорошее правило обладает высокими коэффициентами TР и TN, и низкими коэффициентами FN и FP. Коэффициенты CF и Comp, отвечающие за ошибки первого и второго рода, объединяются в одну фитнесс-функцию, аддитивно с весами w1 и w2
Определим коэффициент покрытия примеров. Для этого количество примеров, правильно отобранных и частью условием, и частью заключением правила назовем
Количество правильно отобранных примеров - это количество примеров, степень активации подусловия для которых больше некоторого значения W и степень активации подзаключения также больше этого порога. Если степень активации подусловия больше W, а подзаключения меньше W, то такой пример считается отобранным неправильно.
Определяем штрафную составляющую фитнесс-функции для уменьшения степени покрытия отрицательных примеров.
Еще одна точностная составляющая отвечает за степень покрытия положительных примеров.
Где Составляющая, отвечающая за симметричность правил
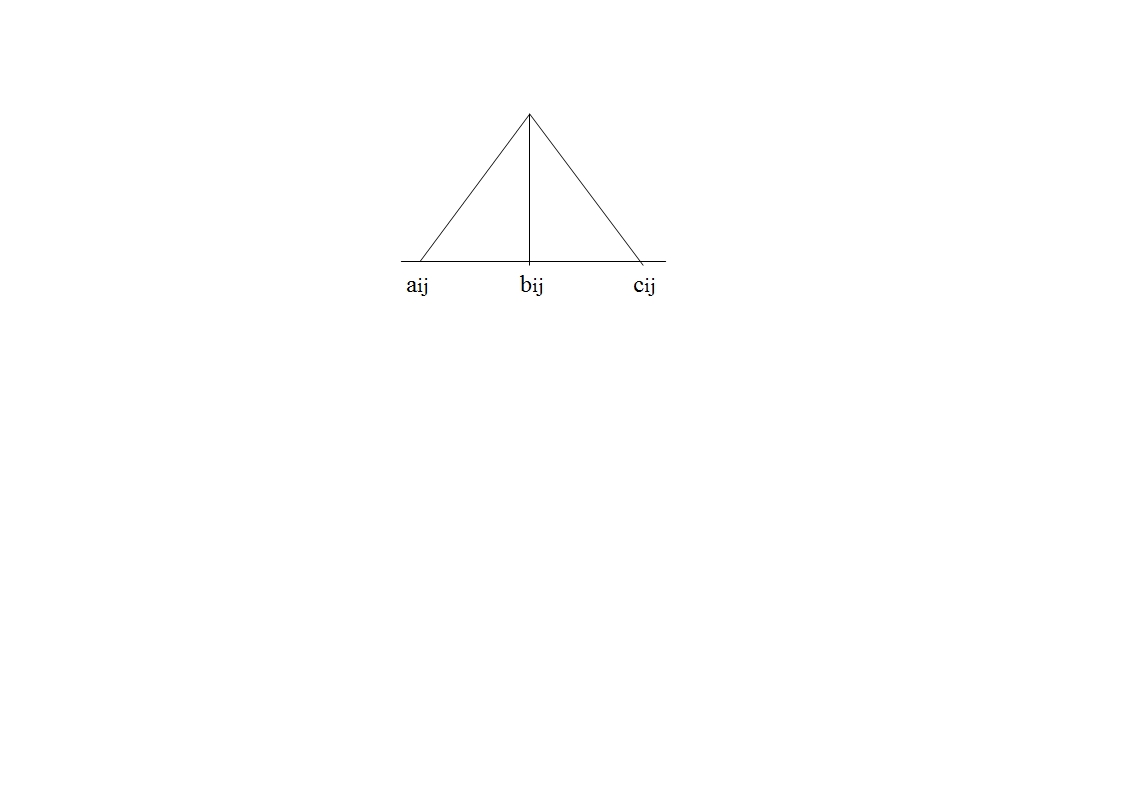
n – число входных переменных и одна выходная Данное составляющее ищет максимальную неравнобедренность треугольников функций принадлежностей подусловий (и подзаключений). Оно равно 1 только в случае, если все функции принадлежностей описаны идеальными равнобедренными треугольниками. Также следует выделять правила, которые не активируются ни на какой точке обучающей последовательности, или активируются всегда. В первом случае может быть удалено одно из подусловий правила, во втором – удалено полностью все правило. Применение эволюционных алгоритмов на этапе постпроцессинга Классическая задача постпроцессинга – модификация уже созданного набора правил с целью достижения максимального его качества. Далее рассмотрены приемы, используемые на этапе постпроцессинга. Мультисимплификация После создания базы знаний (набора нечетких правил) необходима процедура упрощения и сокращения правил, симплификация. Она выполняется с помощью ГА. Её задача – максимально сократить набор правил без существенного ухудшения качества прогноза. Хромосома имеет r двоичных генов, где r – количество правил в наборе. 1 на i-том месте говорит о том, что i-тое правило включено в сокращенный набор, 0 – о том, что i-тое правило не включено. Генетические операторы – классические. Фитнесс – функция - MSE прогноза. На этом этапе используется понятие величины покрытия для проверки полноты использования набором правил обучающей выборки:
где t - минимальная величина покрытия правилами одного примера из ОВ. Если найти величину покрытия для всех точек:
то получим характеристику полноты покрытия данными правилами точек ОВ. При превышении общей величины покрытия порога t считается, что набор правил хорошо подстроен под ОВ, иначе необходимо ввести штрафную составляющую:
Мультисимплификация В процессе симплификации находится один субоптимальный набор правил: для исследования пространства наборов процесс запускается несколько раз, фитнесс-функцию необходимо. Обозначим dh разрешенным расстоянием по Хеммингу хромосомы Cj и найденными решениями Sm={sm1,…,smk}, а rs – радиусом ниши, которую должно занимать решение. Функция расстояния:
где b - степенной фактор, определяющий, вогнутой (b>1) или выпуклой (b<1) будет кривая зависимости. Максимум функции G - при совпадении хромосомы с уже найденным решением, минимум – при значительном отдалении хромосомы от любого из найденных решений (больше, чем rs). Окончательный вид фитнесс-функции процесса мультисимплификации:
В процессе мультисимплификации находится несколько непохожих решений-кандидатов для дальнейшего улучшения. Модификация фитнесс-функции для уменьшения числа правил Главной целью процедуры мультисимплификации является повышение точности набора правил. Одной из целей работы является получение интерпретируемого прогноза, что требует сокращения числа правил. Для этого впервые для генетических нечетких продукционных систем в фитнесс-функцию введено составляющее, отвечающее за сокращение количества правил (0.3):
где wl – определяемый пользователем коэффициент (важности краткости БЗ). Параметр wl регулирует поиск более коротких решений в ущерб точности. возможно значительно сократить число правил, сохраняя точность высокой. Применение неравнозначности правил, их «взвешивание» Классически для получения прогноза сначала ищется набор правил Bg, затем результаты Настройку «весов» правил может выполнять ГА. Количество генов в хромосомах популяции равно количеству правил в наборе, гены хранят информацию о «весе» правила, который может принимать значение в пределах от 0 до 2, базовый вес - 1. Генетические операторы могут быть использованы как из двоичного представления хромосомы (классический и uniform кроссинговер), так и из вещественного (мин-максный кроссинговер, неравномерная мутация, случайная замена веса). Взвешивание логично проводить или после (мульти)симплификации, или совместно с ней. Процесс окончательной подстройки правил или тюнинг В процедуре генерации знаний и предварительной настройки правил использовался Мичиганский подход кодировки особей. В Мичиганском подходе одна хромосома кодирует одно правило, набор хромосом кодирует набор правил. Для процедуры тюнинга используется Питтсбургский подход – одна особь кодирует все правила. В М.П. для 3 вх перем и 1 вых длина хромосомы (особи) = 4*3=12 вещественных чисел. В Питтсбургском подходе для набора из 30 правил длина 1 особи будет равна 30*12=360 вещественных чисел. Входной информацией являются результаты работы этапа (мульти)симпликации. Сокращенную там популяцию используют для кодирования 1-й хромосомы из популяции. Из особей оставляются только части хромосом С2, которые склеиваются в одну мультихромосому. При количестве особей в сокращенной популяции = m, длина мультихромосомы равна m*3*(n+1). Находится ct – самый левый ген из каждой нечеткой ФП подусловия, где t берется из условия: (t mod 3)=1, где mod – операция остатка от деления. Определяются разрешенные интервалы:
Используя эти интервалы, все особи популяции, кроме первой, создаются случайно. Далее следует запуск ГА, использующего мин-максный кроссинговер и неравномерную мутацию. Фитнесс-функцией выступает классическая MSE. Результатом работы процедуры тюнинга является база знаний свободной семантики, в отличие от процессов мультисимплификации и взвешивания, которые могут получать и лингвистически понятный результат. Для увеличения качества прогнозирования была модифицирована процедура -тюнинга путем добавления ЭС в качестве одного из генетических операторов. В [Ошибка! Источник ссылки не найден., Ошибка! Источник ссылки не найден., Ошибка! Источник ссылки не найден.] показаны различные эволюционные стратегии. Также в аналогичных системах была показана применимость ЭС, но только для этапа генерации [Ошибка! Источник ссылки не найден.]. Использование эволюционной стратегии на этапе генерации данной информационой системы показано в п. Ошибка! Источник ссылки не найден. и в [Ошибка! Источник ссылки не найден.]. Данный тип ЭС применим и для этапа тюнинга: кодирование хромосом на этих этапах схожее. ЭС использовалась после каждого шага выполнения кроссинговера и мутации. Экспериментальное доказательство эффективности внедрения ЭС приведено в табл. 4.16 п. Ошибка! Источник ссылки не найден. и опубликовано в [Ошибка! Источник ссылки не найден.]. Полная схема эволюционного алгоритма для автоматического создания базы нечетких правил После определения последовательности создания ИТ и разработки методов для предварительной обработки данных (раздел 2), необходима разработка методов создания БЗ на основе нечетких продукций. Создание заключается в структурном и параметрическом синтезе системы нечеткого вывода. На этапе структурного синтеза лучшей была признана двухуровневая система: нижний уровень создает правила, верхний – собирает их и заботится о их качестве. Параметрический синтез системы нечеткого вывода (создание самих правил) целесообразно выполнять эволюционному алгоритму: классические методы получения правил дают низкую точность, а градиентные методы для задачи такой размерности зачастую ведут к субоптимальному, недостаточно точному решению. Особого внимания в процессе создания ЭА заслуживает фитнесс-функция. Базы знаний, созданные с использованием существующих фитнесс-функций, не показывают достаточную точность. Использование J-меры как основной точностной составляющей компонента фитнесс-функции позволяет исправить этот недостаток. Одним из направлений модификации двухуровневой системы нечеткого вывода
. Двухуровневый ГА автоматического создания набора нечетких правил Создание популяции нижнего уровня эволюционного алгоритма. Треть правил популяции создаются, подбирая индексы части С1 хромосомы (выбираются термы ЛП, лучше соответствущие точкам ОВ, часть С2 берется из ФП терма). Треть правил создается подбором лучшего терма с помощью части С1 хромосомы, часть С2 создается случайно в разрешенных пределях. Треть правил создается полностью случайно. Далее запускается ГА нижнего уровня. Критерием остановки является неулучшение результата заданное число эпох или достижение популяцией определенного возраста. Результатом работы нижнего ГА является лучшее правило Rr, копируемое в массив Bg правил БЗ. Функции верхнего уровня генетического алгоритма. Верхний уровень ГА инициирует работу нижнего. После получения лучшей хромосомы от нижнего ГА запускается новый нижний алгоритм, получается новая особь. Останавливается процесс генерации правил (генерации знаний) после достаточного описания правилами базы знаний всех точек ОВ. Для этого ОВ делится на две части: уже описанную созданными правилами и еще ими не описанную. При создании правила, описывающего (покрывающего) данную точку её переносят из второй подвыборки в первую. В случае нечетких правил такой перенос используют при множественном вхождении точки. Для точки el считается количество вхождений в различные правила - величина покрытия CV:
При достижении Критерий окончания создания набора правил или полное описание правилами точек выборки, или невозможность найти новое правило. |
|
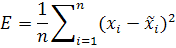
 – действительное значение величины
– действительное значение величины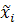 – спрогнозированная величина
– спрогнозированная величина – количество примеров обучающей выборки
– количество примеров обучающей выборки
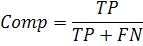
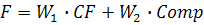




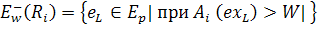
 - точка из обучающей выборки Ep
- точка из обучающей выборки Ep - часть (входная) точки из обучающей выборки
- часть (входная) точки из обучающей выборки - значение активации подусловия [0…1]
- значение активации подусловия [0…1]
 - некоторый задаваемый коэффициент
- некоторый задаваемый коэффициент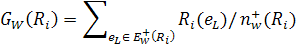
 - степень активации правила точкой eL из обучающей выборки Ep
- степень активации правила точкой eL из обучающей выборки Ep

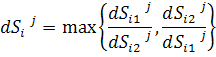

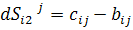
 ,
, .
.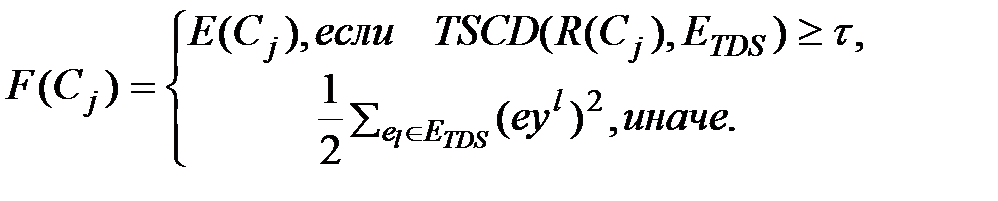
 , (0.1)
, (0.1) . (0.2)
. (0.2) , (0.3)
, (0.3) - число правил, оставленных хромосомой из набора;
- число правил, оставленных хромосомой из набора; , выдаваемые этими правилами для значений exl, усредняются для получения одного значения прогноза. Но существуют ситуации типичные, на которые настроены одни правила из набора, и ситуации нетипичные, редко встречающиеся, на которые реагируют другие правила. Известно, что использование весов правил дает возможность лингвистическим нечетким моделям справляться с неэффективными и/или избыточными правилами. Формально настройка весов W заключается в нахождении таких значений
, выдаваемые этими правилами для значений exl, усредняются для получения одного значения прогноза. Но существуют ситуации типичные, на которые настроены одни правила из набора, и ситуации нетипичные, редко встречающиеся, на которые реагируют другие правила. Известно, что использование весов правил дает возможность лингвистическим нечетким моделям справляться с неэффективными и/или избыточными правилами. Формально настройка весов W заключается в нахождении таких значений  , при которых
, при которых  для всех
для всех  , где r – число правил, и всех
, где r – число правил, и всех  , где Ep – некоторое множество точек.
, где Ep – некоторое множество точек. ,
, ,
, .
. ,
, некоторого порога (например, 1.5) el удаляется из множества обучающих точек ETDS., вновь получаемые правила её уже не учитывают.
некоторого порога (например, 1.5) el удаляется из множества обучающих точек ETDS., вновь получаемые правила её уже не учитывают.